

Enhancing wildfire detection: a novel algorithm for controllable generation of wildfire smoke images
Yinuo Huo A B , Qixing Zhang A * , Chong Wang A , Haihui Wang A and Yongming Zhang A
A * , Chong Wang A , Haihui Wang A and Yongming Zhang A
A
B
Abstract
The lack of wildfire smoke image data is one of the most important factors hindering the development of image-based wildfire detection. Smoke image generation based on image inpainting techniques is a solution worthy of study. However, it is difficult to generate smoke texture with context consistency in complex backgrounds with current image inpainting methods.
This work aims to provide a wildfire smoke image database for specific scenarios.
We designed an algorithm based on generative adversarial networks (GANs) to generate smoke images. The algorithm includes a multi-scale fusion module to ensure consistency between the generated smoke and backgrounds. Additionally, a local feature-matching mechanism in the discriminator guides the generator to capture real smoke’s feature distribution.
We generated 13,400 wildfire smoke images based on forest background images and early fire simulation from the Fire Dynamics Simulator (FDS).
A variety of advanced object detection algorithms were trained based on the generated data. The experimental results confirmed that the addition of the generated data to the real datasets can effectively improve model performance.
This study paves a way for generating object datasets to enhance the reliability of watchtower or satellite wildfire monitoring.
Keywords: controllable smoke image generation, deep learning, Fire Dynamics Simulator, generative adversarial network (GAN), image inpainting, image smoke detection, numerical simulation.
Introduction
The frequency and intensity of wildfires have increased with global climate changes, posing serious challenges to environmental protection and public safety. Effective wildfire monitoring is crucial in mitigating the damage caused by wildfires. However, traditional methods of wildfire detection, such as satellite monitoring and ground observations, face various limitations, including delays in obtaining data, resolution constraints and limited coverage (Bowman et al. 2009). These issues often result in delayed and inaccurate responses to wildfire behaviours, thereby affecting the initial suppression of fires and efficiency in resource allocation (Moritz et al. 2014). Among various techniques, digital image-based smoke recognition has emerged as an efficient method for early wildfire detection. This approach benefits from advances in deep learning technology, which has revolutionised the field of image analysis in recent years (Akhloufi et al. 2018). Deep learning’s capacity to extract complex features from images makes it particularly suitable for detecting subtle signs of smoke in diverse forest landscapes. Consequently, an increased number of researchers are focusing on developing image smoke detection technologies powered by deep learning algorithms (Vinay and Jain 2022).
Despite the promising potential of deep learning for smoke detection, the technology’s effectiveness is significantly hampered by the availability of training data. A robust deep neural network relies on extensive image datasets to learn from. However, the existing datasets for wildfire smoke are limited in size and lack sufficient scene diversity, undermining the development of effective smoke detection models. The scarcity of these data makes it difficult to train models suitable for wildfire smoke detection based on existing public datasets of fire smoke. False positives induced by fog and haze also render them less effective in real-world applications. Moreover, the absence of a standardised, scenario-rich dataset for wildfire smoke makes it challenging to conduct accurate comparative evaluations of different smoke detection algorithms. The deficiency of comprehensive and diverse training data thus represents a major obstacle in advancing image smoke detection technologies.
Currently, there are two ways to obtain wildfire smoke images. The first is to shoot the real fire scene directly. Because of the accidental occurrence and rapid development of fires, it is difficult to shoot smoke images in the early stage of a fire in a timely manner. The second is to simulate fire scenes for ignition experiments and then shoot images. However, forest plantations, national forest parks, nature reserves and other places with fire prevention requirements do not have the conditions for ignition experiments, so smoke images obtained through ignition experiments cannot fully meet the needs of actual wildfire detection (Mohapatra and Trinh 2022). To address the challenge of acquiring fire smoke image data, researchers have explored various methodologies for generating synthetic smoke imagery. Genovese et al. (2011) introduced a technique for creating synthetic wildfire smoke image sequences, utilising the lattice Boltzmann model in conjunction with computer graphics. Cheng et al. (2019) employed Adobe Photoshop to fabricate base masks that mimic ascending smoke, which were subsequently superimposed onto smoke-free images to procure the desired smoke image data. Further, Xie and Tao (2020) developed two distinct neural networks capable of generating controllable smoke images. These networks allow for the production of smoke images with specific smoke components, achieved by altering latent codes corresponding to particular smoke constituents.
Owing to the difficulty in producing visually realistic synthetic smoke images, there are few research works on the application of synthetic smoke images to fire detection. Most of them use image processing software or 3D modelling software to simulate smoke and then add the foreground of smoke to the background image to obtain a synthetic smoke image. A small number of researchers have used generative adversarial networks (GANs) to produce synthetic smoke images. For instance, Labati et al. (2013) pioneered this effort by employing a method based on lightweight physical models and image processing technology, synthesising wildfire smoke images to train detection algorithms. This approach, however, did not address in depth the domain gap between synthetic and real imagery. Building on this, Xu et al. (2017) advanced the methodology by utilising Blender for generating a vast array of synthetic smoke images, integrating these with deep convolutional neural networks through a domain adaptation structure. This significant improvement aimed to mitigate the discrepancies between synthetic and real images. Similarly, Zhang et al. (2018a) contributed to this domain by combining real or simulated smoke with forest backgrounds, employing these images to refine Faster Region-based Convolutional Neural Network (Faster R-CNN)’s effectiveness in smoke detection.
Further elaborating on data augmentation, Namozov and Im Cho (2018) explored traditional techniques alongside GAN to expand the smoke image dataset, addressing overfitting issues encountered when training on limited data. This strategy underscored the critical need for diversified training materials to enhance model robustness. Further, the work of Yuan et al. (2019a, 2019b) delved into deep smoke segmentation and density estimation algorithms. Faced with the arduous task of manually labelling ambiguous smoke images, they proposed an innovative synthetic image generation method, facilitating the creation of segmentation and density estimation samples. This approach represents a shift towards solving practical challenges in smoke detection, emphasising the importance of synthetic data for training purposes. Mao et al. (2021) introduced a methodology to train deep learning classification models on real wildfire smoke using synthetic images. By simulating smoke with 3D modelling software and merging these images with wilderness backgrounds, they crafted a comprehensive synthetic wildfire dataset. The application of pixel-level and feature-level domain adaptation methods crucially aimed to bridge the gap between synthetic and real data, highlighting the evolution towards more effective domain transfer strategies. Wang et al. (2022) demonstrated the utility of combining real and synthetic smoke images to form a hybrid dataset, training an enhanced smoke detection model based on YOLOv5.
Although the physical laws of smoke diffusion are taken into account when using image processing software or 3D modelling software to make synthetic smoke images, there are differences in the deeper features between the synthetic and real smoke images. Therefore, the performance of the smoke detection model is not greatly improved when using such synthetic smoke images as training data. In contrast, GAN can learn deep image features from real smoke images in adversarial training, and then use the learned features to generate new images. Theoretically, fake smoke images close to the real ones can be obtained to solve the problem of insufficient data in the study of image smoke detection. In addition, GAN has the advantages of flexible network architecture, mature technology ecology and high computing efficiency (Chakraborty et al. 2024). However, GAN has some problems, such as training instability, gradient disappearance and mode collapse. The smoke in the image is translucent and has no fixed shape, and the existing GANs have difficulty generating smoke texture with context consistency in a complex forest background. Thus, it is necessary to design a deep network dedicated to the synthesis of smoke images according to the characteristics of smoke.
In an effort to resolve the aforementioned issues, this study employs Computational Fluid Dynamics (CFD) technology to simulate the initial characteristics of smoke in wildfire scenarios. The combination with GAN technology has the possibility to generate images with highly realistic smoke profiles against specified background images. These generated images not only reflect the dynamic dispersion patterns of wildfire smoke but also exhibit clear visual distinctions from fog and haze caused by natural or anthropogenic phenomena. Through this innovative approach, we can rapidly generate a large volume of smoke images with specific scene characteristics, providing a rich and targeted dataset for training wildfire smoke detection models. Specifically, a smoke image generation algorithm based on a specified background and contour is proposed and a multi-scale extended fusion GAN is designed. A smoke segmentation dataset is made for generating network training, and the dataset can also be used for training smoke image segmentation networks. Based on the proposed algorithm and Fire Dynamics Simulator (FDS) simulation results, 13,400 wildfire smoke images were generated, and it was observed that the addition of the generated images to the real dataset improved the performance of the object detection model by ~2–3%.
The rest of this article is arranged as follows: in the second part, we outline the relevant research related to this study; in the third part, we introduce our proposed method in detail, including generating the network structure and constructing the loss function; in the fourth part, the datasets and experiments of this work are introduced; in the fifth part, the experimental results are analysed; and the last part is the conclusion.
Related work
The proposed method is implemented based on GANs. The concept of GANs was first introduced by Goodfellow et al. (2014). The system consists of a generating network and a discriminative network. The generating network takes random vectors as input and outputs fake images, while the discriminant network is responsible for judging the authenticity of the input images. The two networks are trained alternately to improve performance together in the confrontation, and finally, the output image of the generated network is close to the real image. Since then, researchers have developed various GANs based on this idea. Radford et al. (2015) introduced convolution operation into GANs and adjusted the network architecture to resolve the problem of unstable training, which greatly improved network performance. In a parallel vein, Mirza and Osindero (2014) introduced condition variables into the network input and proposed a generative adversarial model with constraints, which could control the content of generated images to a certain extent. This means that we can control the generation of smoke images by designing reasonable constraints.
In the application of GANs, researchers have done a lot of innovative work, and put forward a variety of image processing technologies based on GANs. Isola et al. (2017) took the corresponding images as the input of the generator and discriminator respectively, and proposed the image translation technology Pix2Pix, which belongs to a kind of conditional GAN. The input is images instead of random vectors to obtain the expected generated images. Wang et al. (2018a) improved Pix2Pix by developing a coarse-to-fine generator and a multi-scale discriminator to successfully synthesise high-resolution realistic images. For the smoke image generation task, we can use this method to increase the controllability of the generated results by setting the corresponding background image and smoke image.
It is necessary to generate the texture of smoke in a certain part of the background image to make the newly generated content better integrate with the background. We think that image inpainting technology is very suitable for this task. At present, few researchers have applied GANs to image inpainting. In the study of Iizuka et al. (2017), a method was proposed for image completion by using global and local context discriminators to assess the consistency of the completed image. This approach enables the missing parts of an input image to be filled in a way that ensures both global coherence and local detail consistency. By further refining feature extraction techniques, Yang et al. (2017) used the pre-trained Visual Geometry Group (VGG) model to extract image features and realise multi-scale image inpainting from coarse to fine. Banerjee et al. (2020) introduced a multi-scale GAN for image inpainting, which performs virtual background completion on a single face image through multiple cascading network modules.
Moreover, the integration of semantic segmentation information into an inpainting algorithm has been shown to guide GAN in generating content for missing regions by predicting their labels (Song et al. 2018). A two-stage generative network was proposed by Yu et al. (2018): first generate coarse outcomes, followed by refinement through an attention-equipped network, thus enhancing result quality. The incorporation of edge information into features has also been suggested to ensure more structurally coherent image completions (Li et al. 2019). To reduce computational demands, Sagong et al. (2019) proposed a parallel path generation network for image semantic inpainting, which has lower computational cost compared with the two-stage network.
To balance the equilibrium between structure and texture in image restoration, a mutual encoder–decoder with feature balance was developed (Liu et al. 2020). Hui et al. (2020) proposed a single-stage model with dense dilated convolution structure to solve the problem of unreasonable structures in image inpainting results. Wan et al. (2021) generated the structural information of the missing part of the image through a transformer, and then used convolutional neural networks to generate detailed texture. Zeng et al. (2021) proposed a joint training method for the auxiliary context reconstruction task, which used context information to make the output result of the generator without an attention mechanism more reasonable. Quan et al. (2022) proposed a three-stage image inpainting framework with local and global optimisation. Firstly, an encoder–decoder network with jump connection was used to obtain approximate results, and then a shallow deep model with a small receptive field was used for local refinement. Finally, an attention-based encoder–decoder network with a large receptive field was used for global optimisation. Zheng et al. (2022) proposed a multivariate image completion framework based on VQGAN, which represented images in discrete latent domains through a code-sharing mechanism to effectively learn how to synthesise images in discrete code domains.
Methods
Method process overview
The proposed conditional multi-scale deep fusion GAN consists of a generator and a discriminator. The input of the generating network is a smoke-free background image and a smoke contour mask as a constraint condition. The realistic smoke image is generated in the mask area of the input image by image inpainting.
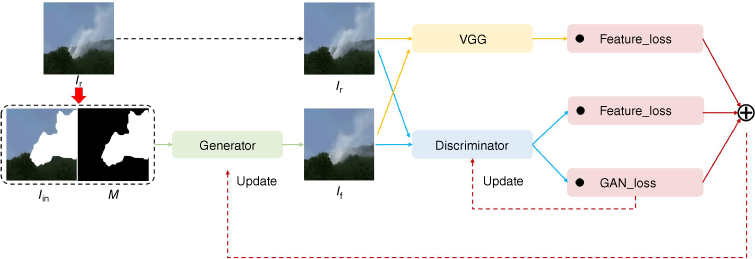
The model training process is shown in Fig. 1. The input of the generated network is the smokeless background image Iin, deducting part of the area and the corresponding binary mask M, where M has the same size as Iin. The pixel values of the subtracted area are 1.0, and the pixel values of the remaining area are 0. The corresponding real smoke image is Ir. As it is difficult to obtain the corresponding smoke and its background image, we obtained the smokeless background image by deducting the smoke part of the smoke image, i.e. Iin = Ir(1 − M), where If is the fake image output from the generator, and If and Ir are input into the discriminant network, respectively. The adversarial loss and feature loss are obtained by comparing the output results of the discriminant network and the feature tensors at all levels. To accelerate model training, we also introduced the pre-trained VGG model. The model is used to extract the image features of If and Ir, and obtain the VGG feature loss. The specific loss function design is introduced in detail below. The generative and discriminative models are optimised alternately to improve performance in the confrontation.
An illustration of the model training procedure. The corresponding background and smoke mask are obtained through the real smoke image. The adversarial loss and feature loss are used to update the generator parameters, and the adversarial loss is used to update the discriminator parameters.
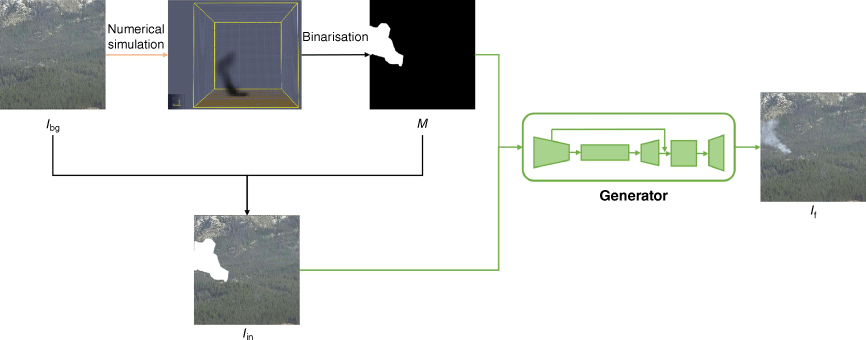
The flow for using the generative model is shown in Fig. 2. For scenarios that require fire safety, such as airports, residences, and schools, we need fire scene images to train the smoke detection algorithm to ensure safety. However, as conducting combustion tests in these environments is not feasible, we only need to collect the background image Ibg of the scene. FDS is used to simulate smoke diffusion results under different fire conditions in the scene. The smoke contour mask M is obtained by processing the visualisation results of smoke diffusion simulation in this scene. The input Iin of the generator is obtained from Ibg and M, where Iin = Ibg(1 − M). The generator will output a near-real composite smoke image If of the specified scene and the smoke outline.
Smoke generation and discriminative network structure
For the smoke image generation task, appropriate features need to be extracted from the background outside the contour to generate reasonable image content, so the receptive field of the convolution kernel used for feature extraction should be large enough. However, directly increasing the size of the convolution kernel leads to too many model parameters that are difficult to train. Dilated convolution can increase the receptive field without changing the number of convolution kernel parameters (Yu and Koltun 2015). However, this method is realised by constructing sparse convolution kernels, so many pixels can be skipped during feature extraction, resulting in information loss.
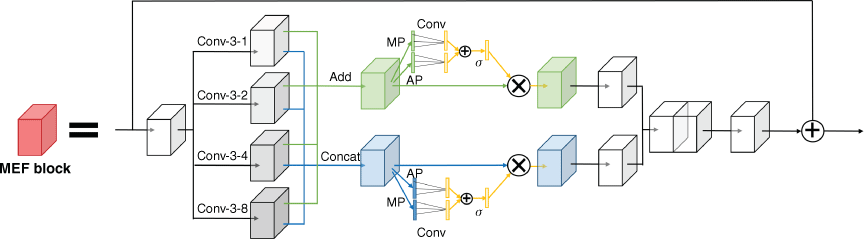
To solve this problem, we designed a multi-scale expansion fusion module, whose specific structure is shown in Fig. 3. The input feature map is extracted by four convolution kernels with different expansion rates, which not only extracts the image features under different receptive fields, but also makes full use of the input information. For the feature maps extracted from four different convolution kernels, we used two methods: addition and concatenation for feature fusion. As there are a large number of redundant features in the fused feature map, we referred to the work of Wang et al. (2020) to generate attention weights for each channel of the feature map, thus improving the effective features and suppressing the redundant features. The specific method is to obtain two feature vectors by global average pooling and global maximum pooling of the fused feature map. Then, the cross-channel information acquisition ability of convolution is used to capture the dependence relationship between channels. Finally, Sigmoid is used to fix the weight between 0 and 1.0. For the generation task, the generated information should be related to the background content of the whole image. If we only focus on the features of a certain region when extracting features, reasonable image content will not be generated. Therefore, we do not introduce a spatial attention mechanism in the feature extractor.
An illustration of the multi-scale expansion fusion (MEF) module structure, including Multi-Scale Pooling (MP) and Average Pooling (AP).
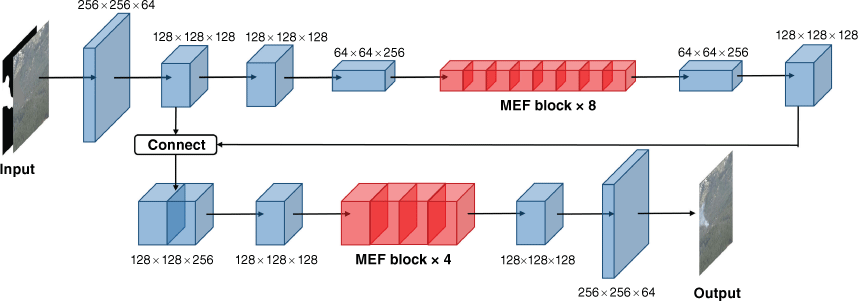
The overall structure of the generator network is shown in Fig. 4. The input of the generator network is a three-channel smoke-free background image and a single-channel smoke contour mask; the output of the network is a complete three-channel smoke image with an image size of 256 × 256 pixels. The encoder of the network consists of four convolutional layers, which downsample the input tensor twice. Except for the first convolutional layer, the batch normalisation layer is set. The size of the feature map after two downsamplings is 64 × 64 × 256. We input the feature map into the deep feature extractor composed of eight multi-scale expansion fusion modules, and the extracted global features can be used to fill the cavity region at a coarse resolution. To more fully extract local features to generate reasonable semi-transparent smoke regions, the result of the second convolution layer of the encoder and the feature map after upsampling of the preliminary filling results are concatenated and fused. The size of the fused feature map is 128 × 128 × 128, which contains rich local background features. We input it into the second deep feature extractor. The deep feature extractor is composed of four multi-scale dilated convolution fusion modules, and the extracted local features are used to fill the cavity more finely.
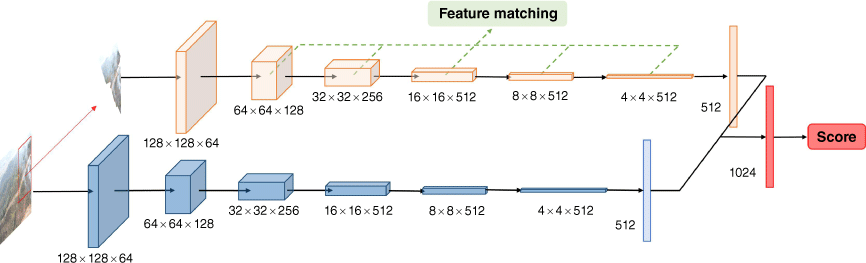
The discriminator network structure is shown in Fig. 5. The network is composed of two branches, which have the same structure and are composed of six convolution layers in series. The input image is subsampled six times to obtain one dimensional vector of length 512. The first branch inputs the complete smoke image and extracts the global features to judge the rationality of the generated image. The second branch only inputs the smoke area in the image and extracts local features to judge the authenticity of the detailed texture of the smoke. The global feature vector is connected with the local feature vector, and the discriminant result of the image is obtained by the input classifier. In addition, in order to evaluate the smoke features of the input image in a high-dimensional space, we referred to the work of Wang et al. (2018b) and output the feature maps for each scale on the branch of the local feature extraction to guide the generation of smoke images.
Loss function
The loss function of the original GAN takes 0 and 1 as labels to train the generator and discriminator. It does not directly optimise the data distribution distance of the true and false images in the high-dimensional space. In the case that the two data distributions do not coincide in the high-dimensional space, it is still possible to meet the requirements of the loss function under the mapping of a certain dimension. Therefore, instability may occur in training. The loss function of ESRGAN (enhanced super-resolution generative adversarial network) (Wang et al. 2018c) takes the difference between the data distribution of true and false images in high-dimensional space as the objective to optimise, which improves the problems described above to a large extent. The loss function form of ESRGAN is as follows:
In Eqn 1, is the loss value of the generator. In Eqn 2, is the loss value of the discriminator, whereas relative monitor DRa(Ir, If) and DRa(If, Ir) have concrete structure as follows:
where S(·) denotes the sigmoid function, and C(·) denotes the results of the discriminator.
To ensure that the feature distribution of the output image of the generator is consistent with that of the real image in high-dimensional space, we compare the feature maps at various scales of the true and false images on the local feature extraction branch of the discriminator to obtain the feature loss at each scale. Loss of discriminant features is given by:
where , represents the local features extracted by the discriminator as the feature map at each scale on the branch, and Nl stands for the number of elements in each scale feature map.
In addition, in order to accelerate network training, we introduce the pre-trained VGG model in model training. At the beginning of training, the feature extraction ability of the randomly initialised discriminator model is insufficient to effectively optimise the generator model, and performance needs to be gradually improved in repeated adversarial iterative training, which takes a lot of time. The pre-trained VGG model has a certain degree of feature extraction ability, which can guide the training of the generator model in the initial stage of training to improve the performance of the discriminator model. We also use a five-level feature loss constraint to train the generator, and the loss value is only used to update the generator during the training process; the VGG model is not updated. The feature loss based on the VGG model is written as:
where Vl(I) indicates each scale feature map extracted from the pre-trained VGG model.
The final loss of generator model includes adversarial loss, discriminator feature loss and VGG feature loss. In addition, to modify the generative model from the outcome level, we add the mean absolute error loss (MAE). The final loss of the discriminator model contains only the adversarial loss. The final loss function of the generator and discriminator is expressed by:
where λ, μ, ν and ξ are the parameters that balance the losses. In this study, we have λ = 0.3, μ = 5, ν = 25, and ξ = 1.
Experimental
Data set production
The real smoke dataset used in this study has a total of 5200 smoke images, of which 5000 were used for training and 200 for testing. Some of them come from publicly available datasets (Shuai et al. 2016). In addition, we conducted a large number of field experiments to supplement the smoke image data. Our experimental scenes included Huangshan Mountain, Zipeng Mountain, Great Khingan, Hongcun and more. Smoke cake, cotton rope, firewood, straw and smoke bombs were used as fuel. The shooting methods were close shooting with a mobile phone, medium and long-distance shooting with a network camera, and long-distance aerial shooting with an unmanned aerial vehicle.
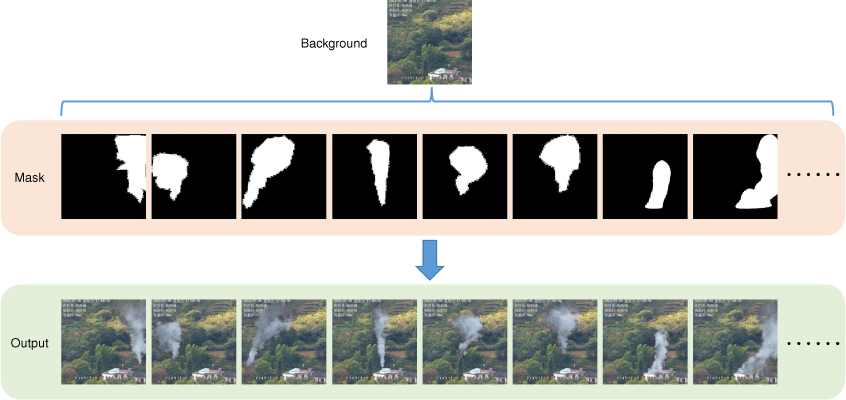
Network training requires a smokeless background image, a smoke contour mask and a target smoke image, and the three kinds of data need to have clear correspondence. As the smoke and its corresponding background image are difficult to obtain, the smokeless background image and smoke contour mask in the dataset were obtained from the real smoke image. We used Labelme software to segment and label the real smoke image, and obtained the corresponding binary mask of the smoke contour after processing. The mask was used to deduct the smoke area in the smoke image to obtain the smokeless background image. The size of all images in the dataset was 256 × 256, and some image data are shown in Fig. 6.

Model training
The proposed network was built using the PyTorch framework. Our operating environment was configured as follows: the operating system was Windows 10 Pro 64-bit; the CPU was an Intel i5-8600k and the GPU was an NVIDIA GeForce RTX 2080 Ti. CUDA 10.0 and CUDNN 7.4.1 were installed on the system. The RAM was 8G with OpenCV version 4.1.1. The training parameters were set as follows: the number of iterations was 100,000, the batch size 8. The initial learning rate of generator and discriminator was 0.0002, and the learning rate decreased by half every 20,000 iterations.
Numerical simulation of smoke diffusion in early fire
In order to test the generality of the smoke image generation algorithm, we used CFD large eddy simulation to numerically simulate the smoke diffusion of early field fires. FDS was selected for this purpose, as it can accurately calculate the smoke diffusion results of the target scene at each moment in a period of time based on fluid mechanics, and display them intuitively through 3D animation. As our ultimate goal was to generate smoke image data that can be used for fire smoke detection, it was necessary to study smoke diffusion in the early stage of a fire.
The main factors affecting smoke diffusion are scene, combustion characteristics of fire source, size of fire source and ambient wind. For the fire scene, fire smoke in an open outdoor area is very little affected by the surrounding buildings and trees at the initial stage, so we do not set up obstacles. The calculation area is set as 20 × 20 × 20 m, and the surrounding and top boundaries are set as open surfaces. For the type of combustion, we chose common wood as the fire source, using the burning characteristics of oak. Release per unit mass oxygen was set to 1.31 × 104 kJ/kg, smoke yield was set to 0.15 Ys (kg of smoke per kg of fuel burned). The size of the burning surface of the ignition source was set to 0.2 × 0.2 m. Recognising that environmental wind speed significantly influences smoke dispersion in the early stages of wildfires, we conducted detailed simulations under three distinct wind conditions (0, 0.5 and 1 m/s). For each wind speed, a minimum of three repeated simulations was performed to ensure the stability and reproducibility of the data, culminating in nine unique CFD simulation cases. The scene modelling and simulation results are shown in Fig. 7.

The texture details of the smoke in the numerical simulation visualisation results are very different from real smoke, but the shape of the smoke is very close to the real situation. We can process the smoke diffusion visualisation results with a specific perspective to make a reasonable smoke contour mask suitable for the target scene. Fig. 8 shows the visualisation results of the smoke diffusion simulation and the smoke contour mask made based on it. The specific method is to first output the smoke diffusion visualisation results at each moment in a specific perspective into image data V, and then convert it to a binary image to obtain the smoke contour mask M via
where mi, j denotes the pixel value of the smoke contour mask M at coordinate (i, j), vi, j stands for the pixel value of the smoke diffusion visualisation results V at coordinate (i, j), and c represents the image channel of V.
Partial visualisation results of smoke diffusion simulation and corresponding smoke contour mask. (a) Visualisation results of smoke diffusion simulation; (b) mask corresponding to simulation results.

From each simulation case, time-series data of smoke dispersion were generated, and smoke contour masks were extracted at 30 distinct time points. In total, this process produced 270 smoke contour masks, from which 150 distinct morphologies were selected for further analysis. Additionally, to enhance sample diversity, 50 true smoke contour masks were manually annotated from real smoke images to supplement this. These masks were subsequently used to generate smoke images that closely mimic real-world scenarios.
Results
Qualitative evaluation
As shown in Fig. 9, our algorithm fills the void area of the input image with reasonable smoke texture, and the output smoke image is different from the real image but realistic enough. Compared with other advanced methods (Yu et al. 2018; Hui et al. 2020; Liu et al. 2020), the smoke images generated here have the best visual effect with no unreasonable stripes, patches and rigid boundaries. It can be seen that our proposed multi-scale dilated convolution fusion module is suitable for the task of large-area smoke texture filling. Multiple convolution kernels with different expansion rates are used for feature extraction at the same time, which can fully reproduce the background information. The fused features are screened through the channel attention mechanism, and finally the translucent and boundary blurred characteristics of smoke can be effectively presented.
Comparisons of image generation algorithm results based on real image background. GT (Ground Truth, real image), CA (Contextual Attention from Yu et al. 2018), MEDFE (Mutual Encoder-Decoder with Feature Equalizations from Liu et al. 2020), DMFN (Dense Multi-Scale Fusion Network from Hui et al. 2020), and MEFN (Multi-Scale Expansion Fusion Network)

Quantitative evaluation
In order to evaluate our generative model more accurately, we used the structural similarity index (SSIM) (Wang et al. 2004), peak signal-to-noise ratio (PSNR) (Sheikh et al. 2006), learned perceptual image patch similarity (LPIPS) (Zhang et al. 2018b) and 1-nearest neighbour classifier (1-NN) (Lopez-Paz and Oquab 2016) to measure the quality of the results.
SSIM comprehensively considers the brightness, contrast and structural differences between two images; it is sensitive to the local differences of images and can quantify the structural similarity between two images. The SSIM results are between 0 and 1, and the closer the result is to 1, the more similar the two images are. SSIM is calculated as follows:
where x and y are the generated image and its corresponding real image respectively. µx and µy are the average value of x and y. σx2 and σy2 are the variance of x and y; σxy is the covariance of x and y; c1 and c2 are related constants, to avoid the denominator being zero. c1 = (k1L)2, c2 = (k2L)2. Here, k1 = 0.01, k2 = 0.03. L is the range of image pixel values, and we have L = 255 in the current work.
PSNR is an image quality metric that measures image distortion by calculating the difference between the maximum signal value of the image and the background. The larger the PSNR, the smaller the image distortion. PSNR is calculated with the following:
where x and y are the generated image and its corresponding real image respectively. MSE(x, y) is mean square error of x and y, and MAXx is the largest pixel values of x.
LPIPS is a learning-based perceptual similarity measurement index that uses depth features to measure image similarity, which is more in line with human perception. The smaller the LPIPS results, the more similar two images are. 1-NN determines the performance of the generator by data distribution. The specific method is to take the partially generated image and the real image as two categories to construct a training set. The same method is used to construct the test set. The trained nearest neighbour classifier is used to classify the test set. If the classifier cannot effectively distinguish between the two types of data (classification accuracy is close to 0.5), it proves that the generated image distribution is consistent with the real image distribution and the generator shows excellent performance. For the indexes above, the evaluation results of our proposed method and other advanced methods are shown in Table 1. Bold values indicate the best results. It can be seen that the proposed method is superior to the existing methods for each index.
Training of object detection network based on generated dataset
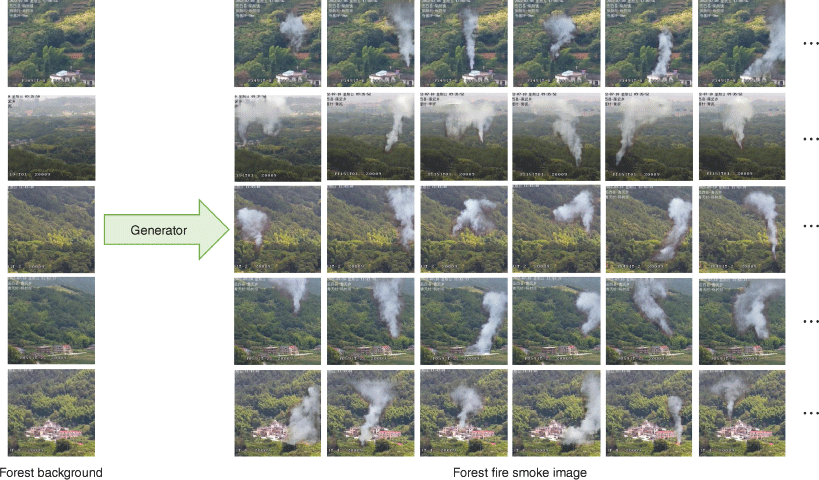
It is necessary to verify whether the generated smoke images can improve the performance of the detection model. We collected smokeless videos of forest scenes at multiple monitoring points from the wildfire prevention monitoring platform in Yuexi County, and obtained 67 forest background images after sorting. There are two ways to obtain the smoke contour mask. One is to obtain the real smoke image by annotation, and the other is to make the smoke contour mask using an FDS simulation. We screened out 200 smoke contour masks. For each background image, we generated 200 different smoke images using the mask. Fig. 10 displays the results of generating a large number of smoke images for a given scene. Using pairwise combinations, we synthesised 13,400 wildfire smoke images. Fig. 11 shows some generated images. As each generated image has a corresponding binary mask, the corresponding label file of the image can be quickly generated by obtaining the minimum outer rectangle of the contour. We organised these 13,400 generated images and their corresponding labelled files into a Visual Object Classes (VOC) format dataset for object detection network training, denoted DS-G.
In order to prove that the images we generated can solve the problem of insufficient real wildfire smoke images, we made 5000 real smoke images into a real image dataset, denoted DS-R. The real and generated images were merged to make a hybrid dataset, denoted DS-M. The test dataset comprises 1000 images from the forest fire monitoring platform in Yuexi County, Anhui Province, evenly split between 500 authentic wildfire smoke images and 500 smoke-free background images. This constant test dataset enables a consistent assessment of detection efficacy. The test dataset harmonises with DS-G, which contains synthetic smoke images created through our methodologies, utilising smoke-free background images from the same monitoring platform. The primary distinction lies in DS-G’s imagery being synthetic whereas the test dataset images are real. This set-up allowed us to validate the effectiveness of generated smoke images in training the object detection model, ensuring that the model can generalise from artificial to real scenarios.
Unlike DS-G, DS-R features fewer real smoke images and different backgrounds compared with the test dataset, thus serving as a control group that reflects the common problem of mismatch between actual scenarios and training data in current wildfire detection methods. It is crucial to note that images from the test dataset are not included in DS-R, nor are they involved in training the generative network, which further supports validity testing of the model across varied datasets. Lastly, DS-M encompasses generated images that share backgrounds with the test dataset, as well as actual smoke images with varying backgrounds. This combination was intended to test whether our method can enhance the precision of wildfire detection under specific scenarios, thereby providing a robust proof of concept for the applicability of our model in diverse environmental settings.
Five advanced object detection networks, i.e. YOLO V4 (Bochkovskiy et al. 2020), CenterNet (Duan et al. 2019), Efficientdet-D1 (Tan et al. 2020), YOLO V8-s (Varghese and Sambath 2024) and RT-DETR-r18 (Zhao et al. 2024), were selected for training and testing. We used DS-R, DS-G and DS-M to train the above object detection networks. The pre-trained model was used for network training, and the number of iterations was set at 10,000. The model detection indicators consist of accuracy rate (Ra), false alarm rate (Rf) and missing detection rate (Rm), and the evaluated results are shown in Table 2. Bold values indicate the best results.
| Method | DS-G | DS-R | DS-M | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ra (%) | Rf (%) | Rm (%) | Ra (%) | Rf (%) | Rm (%) | Ra (%) | Rf (%) | Rm (%) | ||
| YOLO V4 | 89.3 | 11.0 | 10.4 | 92.0 | 7.8 | 8.2 | 93.3 | 6.6 | 6.8 | |
| CenterNet | 88.2 | 11.6 | 12.0 | 91.3 | 9.0 | 8.4 | 92.8 | 7.0 | 7.4 | |
| Efficientdet-D1 | 90.1 | 9.6 | 10.2 | 92.1 | 8.2 | 7.6 | 94.3 | 5.2 | 6.2 | |
| YOLO V8-s | 91.6 | 7.4 | 9.4 | 93.6 | 7.0 | 5.8 | 96.7 | 2.4 | 4.2 | |
| RT-DETR-r18 | 91.1 | 7.0 | 10.8 | 93.1 | 6.2 | 7.6 | 96.0 | 2.4 | 5.6 | |
Bold values indicate the best results.
The results show that the detection model obtained using the DS-M dataset to train the three networks has the best performance, and DS-G dataset has the worst training effect. Although the effect of using only generated data as training samples is not as good as using only real data, the accuracy of the three algorithms is higher than 88%, which indicates that the distribution of the deep features of smoke in the generated image is close to that in the real image, and it can be used as effective data to supplement the dataset. Fig. 12 illustrates the comparative detection results of the YOLO V8 algorithm when trained on DS-R versus DS-M, demonstrating that the inclusion of synthetic data markedly enhances the training effectiveness of the network. Compared with the detection model trained on the DS-R dataset, the detection model trained on the DS-M dataset avoids many missed detections (Rows 3 and 4 in Fig. 12) and false alarms (Rows 5 and 6 in Fig. 12).

Discussion
This investigation demonstrates that the merging of CFD with GAN technologies facilitates the generation of highly realistic smoke images tailored for specific scenarios, thereby substantially improving the robustness of wildfire detection models. As demonstrated by the results in Fig. 12, our methodology guarantees that the synthetic datasets accurately reflect the varied environmental conditions commonly experienced in actual wildfires, thus providing an effective remedy for the lack of real-world smoke data.
Both qualitative and quantitative evaluations substantiate the superior quality of the smoke images produced by our algorithm. Employing rigorous assessment metrics such as the SSIM and PSNR, our images exhibited exceptional fidelity and texture accuracy, surpassing those generated by existing methods. For example, Mameli et al. (2021) introduced a novel approach for enhancing image and video quality through the NoGAN training method, achieving a maximum SSIM of 0.7374. In contrast, our model consistently achieved an average SSIM of 0.9313 (refer to Table 1), reflecting substantial enhancements in visual similarity to actual scenes. Wang et al. (2019) identified that optimised dilation rates can capture comprehensive multi-scale contextual information without resolution loss. Inspired by this understanding, our approach refined the texture generation essential for detailed imagery.
Our innovative multi-scale dilated convolution fusion module, which effectively integrates background information by varying dilation rates of convolutional kernels coupled with a channel attention mechanism advances this field further. By amalgamating these dilated convolutions with a channel attention mechanism, our module adeptly accentuates smoke-relevant features while minimising extraneous background disturbances, thus augmenting the synthetic image quality. This functionality is pivotal for generating images that vividly mimic the visual attributes of real smoke, laying a foundation for training detection models adept at generalising from synthetic environments to actual fire incidents. As highlighted by Yang et al. (2022), the generalisability of synthetic data in training deep learning models for practical applications remains challenging. Models often underperform in real-world conditions owing to their tendency to overfit textural and contextual anomalies present in synthetic datasets. However, our approach mitigates these issues by closely matching the deep feature distributions of real and synthetic images, as evidenced by our model’s enhanced performance in cross-environment tests.
Although the generated smoke images do not precisely replicate the intricate features of actual smoke, they facilitate the rapid production of extensive datasets whose feature distributions closely approximate those of genuine scenes, as exhibited in Figs 10 and 11. This capability allows, to some extent, the replacement of conventional image acquisition methods in specific applications. The efficacy of this strategy is highlighted by the potential to integrate a vast array of synthetic, scene-specific images with a limited collection of actual images to produce a synergistic effect, as revealed by Nikolenko (2021). Our experimental findings reveal that such training equips the detection model to assimilate the feature distributions characteristic of real smoke images effectively (refer to the specific data sources from Yuexi County). This assimilation is further enhanced by deeply integrating both realistic and novel background features from the synthetic images, thus bolstering the model’s robustness in novel scenarios.
The real dataset employed in this study, designated DS-R, contains merely 5000 authentic images and does not adequately represent the diversity of scenarios encountered within the test set. This is indicative of a broader issue in current wildfire detection efforts, where the scarcity of data and lack of scene diversity significantly hamper effectiveness (Alkhatib et al. 2023). When models were trained on the mixed dataset (DS-M), enhanced performance was observed with advanced object detection networks, such as YOLO V8, confirming the benefits of this approach. Specifically, models trained on DS-M exhibited an improvement in performance by approximately 3% compared with those trained exclusively on DS-R (refer to Table 2). Our results indicated that the integration of synthetic data into the training regimen not only mitigates these shortcomings but also significantly amplifies the potential of synthetic imagery to improve the outcomes of model training.
By expanding the quantity and diversity of the training data, our methodology not only boosts the accuracy and reliability of wildfire detection models but also provides a scalable solution that can be adapted to a variety of monitoring requirements, free from the limitations and hazards associated with the acquisition of actual smoke data. This adaptability is pivotal for the deployment of effective wildfire detection systems in remote or otherwise inaccessible areas where gathering real data is impractical. Furthermore, the successful application of this approach in wildfire detection establishes a robust foundation for its potential use in other areas of environmental monitoring and disaster response. The ability of synthetic data to address these challenges may significantly transform the field, enabling the development of more resilient and responsive systems for managing environmental crises and disaster response.
Conclusions
In this paper, we designed a GAN-based smoke image generation algorithm with a multi-scale fusion module, along with a training method that uses specified backgrounds and contours. We used FDS to simulate the diffusion of early fire smoke and made smoke contour masks. Based on these masks, 13,400 visually realistic smoke images were generated with forest scenes in Yuexi County as the background. Through the comparative analysis of multiple groups of experiments, we found that the designed multi-scale expansion fusion generative adversarial network (GAN) can learn the expression of the deep features of smoke on different backgrounds from the training data, and realise reasonable filling of smoke texture in complex backgrounds. The generated smoke image was superior to the existing image completion algorithm in SSIM, PSNR, LPIPS, 1-NN evaluation indices and visual effects.
The feature distribution of the generated smoke image is close to real smoke, and can be used as effective data for training of the smoke target detection algorithm. The mixed training of the generated smoke image based on a specific scene and the real smoke image without the scene can improve the robustness of the detection model. It effectively solves the problems of the small size of existing data sets, insufficient scene richness and difficulty in obtaining data in the field of wildfire smoke image detection. It was proved that it is feasible to train a wildfire image detection model using generated images, and this method is worthy of further development. To further advance research in the field of wildfire detection, we plan to gradually upload the smoke image dataset generated in this study to the website http://smoke.ustc.edu.cn/. Additionally, we aim to continuously expand the dataset to include more smoke images from diverse backgrounds and scenarios, enriching the data resources for this field. In our next work, we will study visible flame image generation and pyrotechnic multispectral image generation algorithms.
Nomenclature
| 1-NN | Nearest neighbour classifier |
| AP | Average Pooling, a down-sampling technique used in convolutional neural networks |
| C(·) | Result of the discriminator |
| c | The image channel |
| c1, c2 | Constants to prevent division by zero in SSIM calculation |
| CA | Contextual Attention |
| CFD | Computational Fluid Dynamics |
| Local features of the discriminator extracting the feature map of each scale on the branch | |
| DMFN | Dense Multi-Scale Fusion Network |
| DRa(·) | Relative distance |
| DS-G | Generated smoke images dataset |
| DS-M | Mixed smoke image dataset |
| DS-R | Real smoke image dataset |
| ESRGAN | Enhanced super-resolution generative adversarial network |
| FDS | Fire Dynamics Simulator |
| GAN | Generative adversarial network |
| GT | Ground Truth |
| Ibg | Background image |
| If | Fake image output from the generator |
| Iin | The smoke-free background image obtained by removing smoke regions from an image |
| Ir | Real smoke image |
| k1, k2 | Small constants, set as k1=0.01 and k2=0.03, used to calculate c1 and c2 to stabilize the SSIM formula. |
| L | The dynamic range of pixel values in the image, for an 8-bit image, L=255. |
| Loss of the discriminator | |
| Loss of the generator | |
| Loss of discriminant featuresF | |
| Feature loss based on the VGG model | |
| LPIPS | Learned perceptual image patch similarity |
| M | Binary smoke mask |
| MEDFE | Mutual Encoder-Decoder with Feature Equalizations |
| MEF | Multi-Scale Expansion Fusion |
| MEFN | Multi-Scale Expansion Fusion Network |
| MP | Max Pooling, a down-sampling technique used in convolutional neural networks |
| mi,j | Pixel value of the smoke contour mask M at coordinate (i, j) |
| MAE | Mean absolute error loss |
| MAXx | Largest pixel values of x |
| MSE(x,y) | Mean square error of x and y |
| Nl | Number of elements in each scale feature map |
| PSNR | Peak signal-to-noise ratio |
| Ra | Accuracy rate of model detection |
| Rf | False alarm rate |
| Rm | Missing detection rate |
| S(·) | Sigmoid function |
| SSIM | Structural similarity |
| vi,j | Pixel value of the smoke diffusion visualisation results V at coordinate (i, j) |
| Vl(·) | Feature map extracted from the pre-trained VGG model |
| VGG | Visual geometry group |
| VQGAN | Vector Quantized Generative Adversarial Networ |
Greek symbols
| λ | Weight parameters of loss of the generator |
| μ | Weight parameters of loss of discriminant features |
| ν | Weight parameters of feature loss based on the VGG model |
| ξ | Weight parameters of loss of average absolute error |
| σx2 | Variance of x |
| σxy | Covariance of x and y |
| σy2 | Variance of y |
| ωl | Weight parameters of local feature loss in layer l |
Data availability
The data supporting this study will be shared on reasonable request to the corresponding author.
Declaration of funding
This work was financially supported by the National Key Research and Development Plan under Grant No. 2021YFC3000300, the National Natural Science Foundation of China under Grant No. 32471866, and the Anhui Provincial Science and Technology Major Project under Grant No. 202203a07020017. The authors gratefully acknowledge all of these supports.
References
Akhloufi MA, Tokime RB, Elassady H (2018) Wildland fires detection and segmentation using deep learning. In ‘Pattern Recognition and Tracking XXIX’. pp. 86–97. (SPIE) 10.1117/12.2304936
Alkhatib R, Sahwan W, Alkhatieb A, Schütt B (2023) A brief review of machine learning algorithms in forest fires science. Applied Sciences 13(14), 8275.
| Crossref | Google Scholar |
Banerjee S, Scheirer W, Bowyer K, Flynn P (2020) On hallucinating context and background pixels from a face mask using multi-scale gans. In ‘Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision’. pp. 300–309. (IEEE) 10.1109/wacv45572.2020.9093568
Bochkovskiy A, Wang CY, Liao HYM (2020) Yolov4: optimal speed and accuracy of object detection. arXiv Preprint arXiv:2004.10934.
| Crossref | Google Scholar |
Bowman DM, Balch JK, Artaxo P, Bond WJ, Carlson JM, Cochrane MA, d’Antonio CM, DeFries RS, Doyle JC, Harrison SP, Johnston FH, Keeley JE, Krawchuk MA, Kull CA, Marston JB, Moritz MA, Prentice IC, Roos CI, Scott AC, Swetnam TW, van der Werf GR, Pyne SJ (2009) Fire in the Earth system. Science 324(5926), 481-484.
| Crossref | Google Scholar | PubMed |
Chakraborty T, Reddy U, Naik SM, Panja M, Manvitha B (2024) Ten years of generative adversarial nets (GANs): a survey of the state-of-the-art. Machine Learning: Science and Technology 5(1), 011001.
| Crossref | Google Scholar |
Cheng HY, Yin JL, Chen BH, Yu ZM (2019) Smoke 100k: a database for smoke detection. In ‘2019 IEEE 8th Global Conference on Consumer Electronics (GCCE)’. pp. 596–597. (IEEE) 10.1109/GCCE46687.2019.9015309
Duan K, Bai S, Xie L, Qi H, Huang Q, Tian Q (2019) Centernet: keypoint triplets for object detection. In ‘Proceedings of the IEEE/CVF International Conference on Computer Vision’. pp. 6569–6578. (IEEE) 10.1109/iccv.2019.00667
Genovese A, Labati RD, Piuri V, Scotti F (2011) Virtual environment for synthetic smoke clouds generation. In ‘2011 IEEE International Conference on Virtual Environments, Human-Computer Interfaces and Measurement Systems Proceedings’. pp. 1–6. (IEEE) 10.1109/VECIMS.2011.6053841
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In ‘Advances in Neural Information Processing Systems. Vol. 27’. (Eds Z Ghahramani, M Welling, C Cortes, N Lawrence, KQ Weinberger) pp. 139–144. (Curran Associates, Inc.) 10.1145/3422622
Hui Z, Li J, Wang X, Gao X (2020) Image fine-grained inpainting. arXiv Preprint arXiv:2002.02609.
| Crossref | Google Scholar |
Iizuka S, Simo-Serra E, Ishikawa H (2017) Globally and locally consistent image completion. ACM Transactions on Graphics (ToG) 36(4), 1-14.
| Crossref | Google Scholar |
Isola P, Zhu JY, Zhou T, Efros AA (2017) Image-to-image translation with conditional adversarial networks. In ‘Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition’. pp. 1125–1134. (IEEE) 10.1109/cvpr.2017.632
Labati RD, Genovese A, Piuri V, Scotti F (2013) Wildfire smoke detection using computational intelligence techniques enhanced with synthetic smoke plume generation. IEEE Transactions on Systems, Man, and Cybernetics: Systems 43(4), 1003-1012.
| Crossref | Google Scholar |
Li J, He F, Zhang L, Du B, Tao D (2019) Progressive reconstruction of visual structure for image inpainting. In ‘Proceedings of the IEEE/CVF international conference on computer vision’. pp. 5962–5971. (IEEE) 10.1109/iccv.2019.00606
Liu H, Jiang B, Song Y, Huang W, Yang C (2020) Rethinking image inpainting via a mutual encoder-decoder with feature equalizations. In ‘Computer Vision–ECCV 2020: 16th European Conference’, 23–28 August 2020, Proceedings, Part II 16. pp. 725–741. (Springer International Publishing: Glasgow, UK) 10.1007/978-3-030-58536-5_47
Lopez-Paz D, Oquab M (2016) Revisiting classifier two-sample tests. arXiv Preprint arXiv:1610.06545.
| Crossref | Google Scholar |
Mameli F, Bertini M, Galteri L, Del Bimbo A (2021) A NoGAN approach for image and video restoration and compression artifact removal. In ‘2020 25th International Conference on Pattern Recognition’. pp. 9326–9332. (IEEE) 10.1109/ICPR48806.2021.9413095
Mao J, Zheng C, Yin J, Tian Y, Cui W (2021) Wildfire smoke classification based on synthetic images and pixel-and feature-level domain adaptation. Sensors 21(23), 7785.
| Crossref | Google Scholar | PubMed |
Mirza M, Osindero S (2014) Conditional generative adversarial nets. arXiv Preprint arXiv:1411.1784.
| Crossref | Google Scholar |
Mohapatra A, Trinh T (2022) Early wildfire detection technologies in practice – a review. Sustainability 14(19), 12270.
| Crossref | Google Scholar |
Moritz MA, Batllori E, Bradstock RA, Gill AM, Handmer J, Hessburg PF, Leonard J, McCaffrey S, Odion DC, Schoennagel T, Syphard AD (2014) Learning to coexist with wildfire. Nature 515(7525), 58-66.
| Crossref | Google Scholar | PubMed |
Namozov A, Im Cho Y (2018) An efficient deep learning algorithm for fire and smoke detection with limited data. Advances in Electrical and Computer Engineering 18(4), 121-128.
| Crossref | Google Scholar |
Nikolenko SI (2021) ‘Synthetic data for deep learning. Vol. 174.’ (Springer Nature) 10.1007/978-3-030-75178-4
Quan W, Zhang R, Zhang Y, Li Z, Wang J, Yan DM (2022) Image inpainting with local and global refinement. IEEE Transactions on Image Processing 31, 2405-2420.
| Crossref | Google Scholar | PubMed |
Radford A, Metz L, Chintala S (2015) Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434.
| Crossref | Google Scholar |
Sagong MC, Shin YG, Kim SW, Park S, Ko SJ (2019) Pepsi: fast image inpainting with parallel decoding network. In ‘Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition’. pp. 11360–11368. (IEEE) 10.1109/cvpr.2019.01162
Sheikh HR, Sabir MF, Bovik AC (2006) A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Transactions on Image Processing 15(11), 3440-3451.
| Crossref | Google Scholar | PubMed |
Shuai L, Bo W, Ranran D, Zhiqiang Z, Sun L (2016) A novel smoke detection algorithm based on fast self-tuning background subtraction. In ‘2016 Chinese control and decision conference (CCDC)’. pp. 3539–3543. (IEEE) 10.1109/CCDC.2016.7531596
Song Y, Yang C, Shen Y, Wang P, Huang Q, Kuo CCJ (2018) SPG-Net: Segmentation prediction and guidance network for image inpainting. arXiv preprint arXiv:1805.03356.
| Crossref | Google Scholar |
Tan M, Pang R, Le QV (2020) Efficientdet: scalable and efficient object detection. In ‘Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition’. pp. 10781–10790. (IEEE) 10.1109/cvpr42600.2020.01079
Varghese R, Sambath M (2024) YOLOv8: a novel object detection algorithm with enhanced performance and robustness. In ‘2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS)’. pp. 1–6. (IEEE) 10.1109/ADICS58448.2024.10533619
Vinay K, Jain C (2022) Fire and smoke detection with deep learning: a review. i-Manager’s. Journal on Digital Signal Processing 10(2), 22-32.
| Crossref | Google Scholar |
Wan Z, Zhang J, Chen D, Liao J (2021) High-fidelity pluralistic image completion with transformers. In ‘Proceedings of the IEEE/CVF International Conference on Computer Vision’. pp. 4692–4701. (IEEE) 10.1109/iccv48922.2021.00465
Wang C, Xu C, Wang C, Tao D (2018a) Perceptual adversarial networks for image-to-image transformation. IEEE Transactions on Image Processing 27(8), 4066-4079.
| Crossref | Google Scholar | PubMed |
Wang TC, Liu MY, Zhu JY, Tao A, Kautz J, Catanzaro B (2018b) High-resolution image synthesis and semantic manipulation with conditional gans. In ‘Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition’. pp. 8798–8807. (IEEE) 10.1109/cvpr.2018.00917
Wang X, Yu K, Wu S, Gu J, Liu Y, Dong C, Qiao Y, Change Loy C (2018c) Esrgan: Enhanced super-resolution generative adversarial networks. In ‘Proceedings of the European Conference on Computer Vision (ECCV) Workshops’. pp. 1–23. (IEEE) 10.48550/arXiv.1809.00219
Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q (2020) ECA-Net: Efficient channel attention for deep convolutional neural networks. In ‘Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition’. pp. 11534–11542. (IEEE) 10.1109/cvpr42600.2020.01155
Wang Y, Wang G, Chen C, Pan Z (2019) Multi-scale dilated convolution of convolutional neural network for image denoising. Multimedia Tools and Applications 78, 19945-19960.
| Crossref | Google Scholar |
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 13(4), 600-612.
| Crossref | Google Scholar | PubMed |
Wang Z, Wu L, Li T, Shi P (2022) A smoke detection model based on improved YOLOv5. Mathematics 10(7), 1190.
| Crossref | Google Scholar |
Xie C, Tao H (2020) Generating realistic smoke images with controllable smoke components. IEEE Access 8, 201418-201427.
| Crossref | Google Scholar |
Xu G, Zhang YM, Zhang QX, Lin GH, Wang JJ (2017) Deep domain adaptation based video smoke detection using synthetic smoke images. Fire Safety Journal 93, 53-59.
| Crossref | Google Scholar |
Yang C, Lu X, Lin Z, Shechtman E, Wang O, Li H (2017) High-resolution image inpainting using multi-scale neural patch synthesis. In ‘Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition’. pp. 6721–6729. (IEEE) 10.1109/cvpr.2017.434
Yang S, Xiao W, Zhang M, Guo S, Zhao J, Shen F (2022) Image data augmentation for deep learning: a survey. arXiv preprint arXiv:2204.08610.
| Crossref | Google Scholar |
Yu F, Koltun V (2015) Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122.
| Crossref | Google Scholar |
Yu J, Lin Z, Yang J, Shen X, Lu X, Huang TS (2018) Generative image inpainting with contextual attention. In ‘Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition’. pp. 5505–5514. (IEEE) 10.1109/cvpr.2018.00577
Yuan F, Zhang L, Xia X, Huang Q, Li X (2019a) A wave-shaped deep neural network for smoke density estimation. IEEE Transactions on Image Processing 29, 2301-2313.
| Crossref | Google Scholar | PubMed |
Yuan F, Zhang L, Xia X, Wan B, Huang Q, Li X (2019b) Deep smoke segmentation. Neurocomputing 357, 248-260.
| Crossref | Google Scholar |
Zeng Y, Lin Z, Lu H, Patel VM (2021) Cr-fill: generative image inpainting with auxiliary contextual reconstruction. In ‘Proceedings of the IEEE/CVF International Conference on Computer Vision’. pp. 14164–14173. (IEEE) 10.1109/iccv48922.2021.01390
Zhang QX, Lin GH, Zhang YM, Xu G, Wang JJ (2018a) Wildland forest fire smoke detection based on faster R-CNN using synthetic smoke images. Procedia Engineering 211, 441-446.
| Crossref | Google Scholar |
Zhang R, Isola P, Efros AA, Shechtman E, Wang O (2018b) The unreasonable effectiveness of deep features as a perceptual metric. In ‘Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition’. pp. 586–595. (IEEE) 10.48550/arXiv.1801.03924
Zhao Y, Lv W, Xu S, Wei J, Wang G, Dang Q, Liu Y, Chen J (2024) Detrs beat yolos on real-time object detection. In ‘Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition’. pp. 16965–16974. (IEEE) 10.48550/arXiv.2304.08069
Zheng CX, Song GX, Cham TJ, Cai JF, Phung D, Luo LJ (2022) High-quality pluralistic image completion via code shared VQGAN. arXiv preprint arXiv:2204.01931.
| Crossref | Google Scholar |