

Early forest flame and smoke detection based on improved feature extraction module with enhanced image processing inspired by YOLOV7
Ruipeng Han A , Yunfei Liu A * , Xueyi Kong A , Zhihui Qiu A , Shuang Li A and Han Liu BA
B
Abstract
The forest environment is intricate and dynamic, with its depiction influenced by various factors such as geographical location, weather conditions, and capture angles. Relying solely on flame or smoke is insufficient for precise fire information.
This paper proposes a method for accurate detection on forest flame and smoke based on improved feature extraction module with enhanced image processing.
We a fusion-guided filtering image processing method and flame segmentation strategy to augment the quality of dataset. Additionally, an outstanding extraction backbone, incorporating ghost modules and decoupled fully connected (DFC) attention modules, is developed to increase the model’s receptive field. Furthermore, the ELAN-S neck with SimAM attention mechanism is introduced to fuse features from the backbone network, facilitating the extraction of shallow and deep-level semantic information.
Compared to YOLOV7, our model demonstrates superior performance with a 5% increase in mean average precision (mAP), a 4.3% increase in average precision for small objects (APS), and a 3–4% enhancement in other metrics.
The proposed model achieves a good balance between detection speed and detection accuracy. The improved model performs well in real forest fire detection scenarios.
In the early forest fire detection, the model considers both flame and smoke information to describe the fire situation, and effectively combines the semantic information of both for fire warning.
Keywords: DFC attention module, early forest fire detection, feature extraction, fire warning, fusion-guided filtering, image processing, semantic information, SimAM attention mechanism.
Introduction
Forests are widespread across the land surface and are crucial ecosystems. The escalating impact of global climate change has led to a surge in extreme weather events worldwide, resulting in frequent forest fires (Yuan et al. 2015). These fires exhibit rapid spread and prove challenging to control promptly (Dios et al. 2008). Consequently, the timely and accurate detection of fires in their early stages becomes imperative, offering increased response time for firefighting efforts and minimising the associated challenges and losses (Eugenio et al. 2016).
Early detection of forest fire is beneficial to reduce fire losses and protect the ecological environment. Various methods such as manual inspection, ground sensor monitoring, and satellite remote sensing have traditionally been employed for fire detection (Fernandes et al. 2004; Yu et al. 2005; Hossain et al. 2020). However, these approaches are not without shortcomings, particularly in open forest areas. Relying entirely on manual inspection will bring some problems: labour intensity is relatively high, requiring a large number of manpower for continuous monitoring and analysis, and it may be difficult to ensure adequate inspection coverage; the speed of manual inspection is limited, and it is difficult to achieve real time fast response. There may be some inconsistency in the judgement of forest fire, and the judgement criteria and experience of different analysts are different. Sensor-based (Yu et al. 2005; Chen et al. 2007) systems excel in indoor spaces but are cost-prohibitive for outdoor installation. Infra-red or ultraviolet detectors face environmental interference and limited detection range, rendering them unsuitable for expansive open areas. While satellite remote sensing (Lee et al. 2001) excels in detecting large-scale forest fires, it falls short in early regional fire detection.
With the development of computer vision technology, researchers began to seek an efficient fire detection model based on image processing. Ryu and Kwak (2021) used HSV colour conversion and Harris corner detection in the image pre-processing step. They extract nearby upward-facing corner points as regions of interest (ROI). The classifier is then applied to judge whether there is a fire, achieving a low error detection rate. Töreyin et al. (2006) used 1D time wavelet transform to detect flame flicker, and adopted 2D space wavelet transform to identify flame moving region. This method combines the change of colour and time information to reduce false positives in real scenes. Ye et al. (2017) proposed an adaptive background difference method based on space-time wavelet analysis, Weber contrast analysis and colour segmentation, which can extract slow-moving smoke regions. Appana et al. (2017) extracted the motion information of smoke by optical flow method, modelled the motion trajectory of smoke by combining the time series method, then selected candidate regions by analysing the spatio-temporal energy of each pixel, and finally entered the smoke image and spatio-temporal energy features into SVM for training. The above vision-based image processing methods rely heavily on human prior knowledge, and the artificially created features are not enough to describe forest fires in all scenarios, resulting in low recognition accuracy.
Nevertheless, deep learning shows the power to help human to detect forest fire. Deep learning models are used as intelligent monitoring systems on the front end and human analysts are used for verification and decision support on the back end. This humman-machine collaborative approach can give full play to their respective advantages and provide more reliable and comprehensive forest fire detection and emergency response. They excel in learning features surpassing human capabilities, extracting features that possess richer semantic information compared to artificial features. In recent years, deep learning has surpassed traditional handcrafted features in many fields and has been widely applied in fire detection. Frizzi et al. (2016) proposed a Converlutional Neural Networks (CNN) for flame and smoke detection and classification by extracting features from videos. Yang et al. (2020) proposed a lightweight convolutional neural network model integrating Simple Recurrent Units (SRU), adding 3D convolutional layer between CNN and SRU, extracting scene features through convolutional neural network, and using continuous frames to extract flame dynamic features, thus improving the detection accuracy under complex background or strong interference. Lu et al. (2021) proposed a two-stream convolutional neural network (TSCNN) for flame region detection. The input of TSCNN consists of two parts: an input image and a two-frame differential image, which incorporates static spatial features and dynamic temporal features. Pan et al. (2021) use weakly supervised fine segmentation and lightweight Faster R-CNN to introduce a collaborative area detection and grading framework for forest flame and smoke. Traditionally, forest flame and smoke detection studies have focused solely on detecting either flames or smoke. However, the forest environment presents a highly complex scenario, with images influenced by various factors such as weather conditions, geographical location, shooting angles, and inherent characteristics. These variables complicate the extraction of flame and smoke features under diverse circumstances. By simultaneously considering both flame and smoke, a more comprehensive extraction of semantic information pertinent to forest fires can be achieved.
This paper introduces a forest flame and smoke detection method based on multi-feature extraction (Fig. 1). First, an image enhancement method is presented to mitigate the impact of the image background on smoke while preserving edge information based on the semantic information provided by flame and smoke. Utilising the YCbCr colour space (Noda and Niimi 2007), segmentation and extraction are performed on the flame image, isolating regions with similar flame colours and filtering out irrelevant information to enhance network convergence speed. Second, an efficient model is proposed for detecting both flames and smoke, featuring a systematically optimised backbone architecture to reduce redundant feature extraction and enhance accuracy. Attention mechanisms are incorporated into efficient aggregation networks to further enhance the model’s feature extraction capabilities. Finally, a new loss function, SIOU, is applied. This function considers vector angles between required regressions and redefines the penalty term, thereby improving both the training speed and inference accuracy.
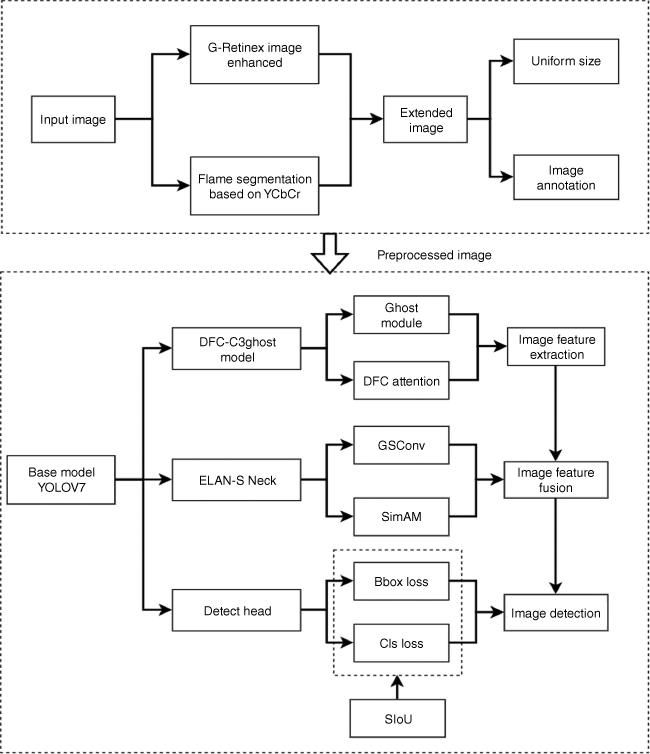
Materials and methods
Dataset
The effectiveness of forest fire detection using convolutional neural networks heavily relies on the quality and scale of the dataset. With high-quality datasets, deep learning models can learn more features and exhibit superior generalisation capabilities. We have gathered over 25,000 images from various public datasets, including BoWFire Dataset (2021), FiSmo (Cazzolato et al. 2017), Firesense (Kucuk et al. 2008), VisiFire (2021), and HPWREN Fire (2020). Our dataset encompasses diverse forest fire images, including different types and scenes, as well as smoke images and non-flame images portraying forest scenes, shadows, sunset glow, and water mist. Fig. 2 shows some representative examples from the dataset (Table 1).

Multi-scale guided filtering Retinex image enhancement method
In this study, we propose a guide filtering method based on Retinex. Due to the different sources of forest flame smoke data and the influence of natural environmental factors from different lighting angles, the obtained smoke images will have uneven lighting and large colour deviation. When these forest flame and smoke images are directly inputted into the detection network, the network may not be able to directly extract the smoke features and distinguish information due to excessive strong light or shadow occlusion, resulting in high false negatives in the detection methods.
In Retinex theory, an image I(x, y) is represented as the multiplication of light layer B(x, y) and reflection layer R(x, y), and principal component analysis (PCA) is used to extract the brightness channel layer of the original image as the light layer. The Single Scale Retinex (SSR) reflector is represented by Eqn 1:
where i represents the ith component of the original image and P represents the PCA operation. The Multi Scale Retinex (MSR) reflector is represent by Eqn 2:
In Eqn 2, N is the number of the scales and ni is the ith component of the nth scale. wn is the nth scale-dependent weight and w1 + … + wn = 1. In this study, N is equal to 3, the three scales are 80, 120, and 250, and w1 = w2 = w3 = 1/3.
In practice, shadow occlusion or light is too strong, the illumination layer of the image will change dramatically, and the direct use of the above method may cause pseudo-halo and detail loss etc. Guided filtering has the ability to protect edge and gradient. Therefore, guided filtering is used to further improve MSR.
A two-level decomposition is performed using guided filtering, expressed as Eqn 3:
where Guilter filter(·) is Guided filtering (GF), rj is the local filtered window radius, and εj is a regularisation parameter introduced to prevent the guiding filter coefficient from becoming too large. We use F1 to represent the image after the first filtering, and F2 to represent the image after the second filtering. The flow of GF-Retinex image enhancement algorithm is in Algorithm 1.
| Algorithm 1. G-Retinex | |
| Input: RGB colour image I(x, y) and three scale numbers: 80, 120, 225 | |
| extract the brightness information of the three colour channels by PCA | |
| begin: | |
| for each R,G,B channel do | |
| for each three scale do | |
| calculation of single-scale reflection results SSRi (x, y) | |
| end | |
| calculation of multi-scale reflection results MSRi (x, y) | |
| use Fourier transform to convert MSRi (x, y) from time domain to frequency domain | |
| the two-stage decomposition is carried out by formula 3 | |
| calculate high frequency information and low frequency information | |
| integrate high and low frequency information to obtain enhanced images | |
| enhance image contrast and stretch contrast | |
| end | |
| end | |
| Output: The enhanced image by G-Retinex |
To prove the effectiveness of the G-Retinex algorithm, three evaluation indexes, are used to evaluate the algorithm: (1) information entropy (IE); (2) peak signal-to-noise ratio (PSNR); and (3) running time. IE is the average amount of information contained in each picture, and the higher the information entropy, the richer the information contained in the image, specifically expressed as Eqn 4:
where p(i) is the probability distribution for all histogram counts. PSNR is an unbiased image quality parameter. The higher the peak signal-to-noise ratio, the better the image enhancement effect. PSNR is expressed as Eqn 5:
where I(x, y) and Ienhanced(x, y) are the former image and enhanced image intensity, respectively. M and W are the height and width of the image, respectively. We selected 100 smoke images in the dataset and compared them with typical image enhancement algorithms. The experiment results are in Table 2.
| Method | Information entropy | PSNR (dB) | Running time (s) | |
|---|---|---|---|---|
| MSR | 7.39 | 23.67 | 2.24 | |
| LB-MSR | 7.44 | 24.51 | 1.74 | |
| NTF | 7.41 | 24.83 | 0.04 | |
| G-MSR | 7.88 | 51.26 | 0.04 |
Retinex algorithm was applied to images with smoke, and the test results are in Fig. 3. A noticeable improvement can be observed when comparing the original smoke image with the MSR-GF method. Particularly, under ample lighting conditions, the MSR-GF method effectively enhances the details of small smoke objects within the image. This enhancement algorithm addresses the issue of missing smoke texture information caused by blurred images with low pixel density. Compared with the SSR method, G-Retinex can improve the confidence of object detection.

Flame segmentation based on YCbCr
Owing to the remarkable learning capacities exhibited by convolutional neural networks, deep learning has become extensively embraced in the realm of object detection tasks. Object detection networks, commonly employed, can be broadly categorised into two groups: (1) one-stage networks; and (2) two-stage networks. One-stage networks, as opposed to their two-stage counterparts, eliminate the necessity of generating proposal regions and instead directly predict the category and location of objects utilising the backbone network. This methodology presents various benefits, including accelerated computation speed and reduced computational costs, rendering it more apt for real world applications.
In Fig. 4, we can intuitively see the difference between the absolute value of Cb and Cr components in the flame region and the non-flame region. According to the comparison of many flame images, the threshold conditions of each component of flame colour in YCbCr space are in Eqn 6:
In Eqn 6, Y(x, y) is luminance value, Cb(x, y) is the blue chrominance signal value, and Cr(x, y) is the red chrominance signal value.
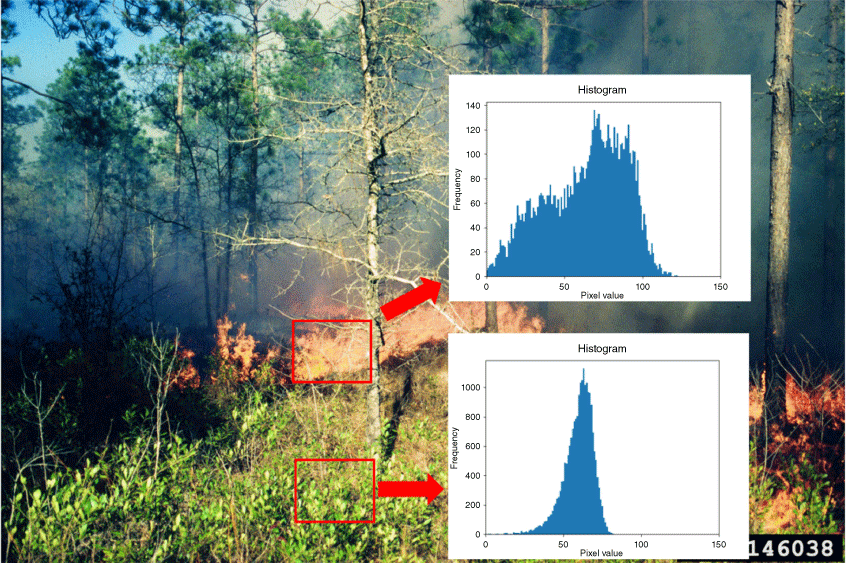
First, the image is converted into a grey value image, set the pixel value of Cb and Cr difference between 110 and 150, and the rest is set to 0. After converting into binary image, the small hole in the image is removed to realise the flame segmentation. The specific process is in Fig. 5.

Architecture of proposed network
Due to the remarkable learning capabilities exhibited by convolutional neural networks, deep learning has gained widespread popularity in the field of object detection tasks. Object detection networks, commonly utilised, can be broadly categorised into two groups: (1) one-stage networks; and (2) two-stage networks. In contrast to two-stage networks, one-stage networks eliminate the necessity of generating proposal regions and directly predict the category and location of objects using the backbone network. This approach presents several advantages, including faster computation speed and lower computational costs, rendering it more suitable for real-world scenarios.
Inspired by the design principles of the YOLO network, we introduce a novel and cost-efficient one-stage convolutional network framework specifically tailored for real time fire detection in this study. The goal is to capitalise on the advantages of one-stage networks, such as their speed and efficiency, to devise an effective solution for real time fire detection scenarios. The comprehensive network model is in Fig. 6.
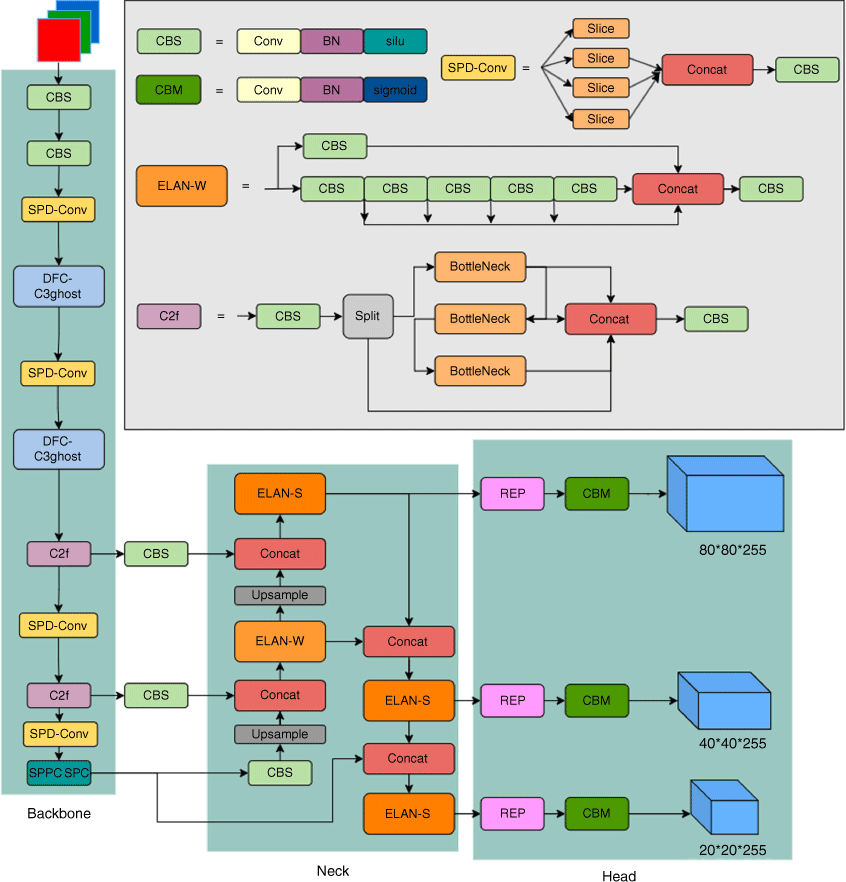
In the context of geographical location and weather conditions, mitigating the impact of environmental factors on the accuracy of fire scene detection, particularly in forest fire scenarios, is imperative. The simultaneous detection of both smoke and flames plays a crucial role in ensuring the prompt and precise communication of fire-related information. Traditional backbone networks typically rely on stacked convolutional blocks for feature extraction, but this often results in a substantial amount of redundant information, leading to decreased accuracy and slower convergence speed. Addressing this challenge and preserving the detection accuracy of lightweight backbone networks necessitates innovative approaches.
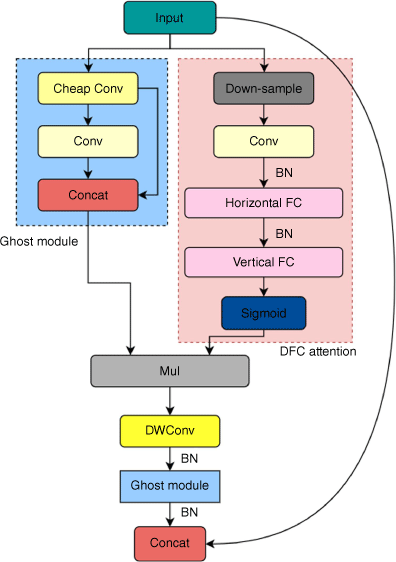
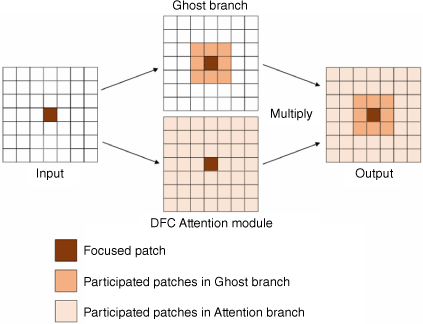
In contrast to the conventional practice of stacking convolution blocks, this paper adopts the DFC-C3ghost module (Fig. 7). This module comprises the ghost module and the decoupled fully connected (DFC) attention mechanism. The ghost module incorporates a residual structure, comprising three steps: conventional convolution, ghost generation, and feature map stitching. The DFC attention mechanism facilitates the generation of attention maps with receptive fields using fully connected layers with fixed weights.
A direct implementation of FC layer to generate the attention map is formulated as Eqn 7:
where ⊙ is element-wise multiplication, F is the learnable weights in the FC layer, and A = {a11, a12, …, aHW} is the generated attention map. The expression of the DFC attention mechanism is formulated as Eqn 8:
where FH and FW are transformation weights. The information aggregation process is in Fig. 8. It involves two parallel branches, namely the ghost module and the DFC attention module, extracting information from different perspectives while utilising the same input. The output is obtained by element-wise multiplication of the features from the ghost module and the attention from the DFC attention module. This combined output contains comprehensive information from both branches, allowing for a more holistic representation.
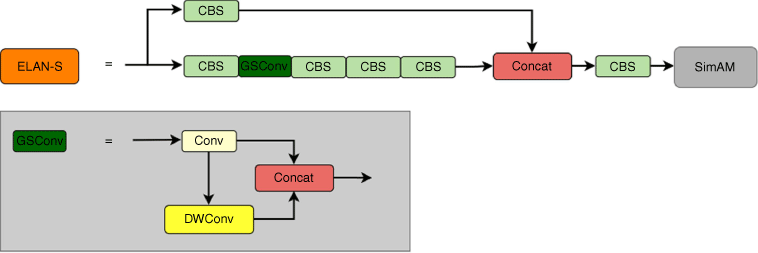
In this paper, we learned from the neck network of YOLOV7 and introduced the optimised PANet network. At the same time, ELAN module has been improved, and the improved ELAN-S module is in Fig. 9.
Attention mechanism is widely used in convolutional neural networks. Traditional attention mechanisms, like CBAM, typically combine spatial attention and channel attention in parallel or sequential manners. However, in the human brain, these two forms of attention often work together synergistically. To achieve more effective attention, it is crucial to evaluate the importance of individual neurons. In neuroscience, information-rich neurons often exhibit distinctive firing patterns compared to neighbouring neurons. Additionally, the activation of neurons generally inhibits the surrounding ones, known as spatial inhibition. As a result, neurons with spatial inhibition should be assigned higher importance. The energy function is defined in Eqn 9:
where t̂ = wtt + bt, x̂I = wtxi + bt. Binary labels are used here, regular terms are added, and the final energy function is defined as Eqn 10:
The analytical solution of this formula is Eqn 11:
and . Therefore, the minimum energy formula is Eqn 12:
The formula means that the lower the energy, the more distinct the neuron t is from the surrounding neuron, and the more important it is. Therefore, the importance of neurons is . And the input features are enhanced by Eqn 13:
where X is input feature and X̃ is on behalf of enhanced features. Based on this formula, SimAM is proposed and good results are obtained. SimAM deduces 3D attention weights for feature graphs without additional parameters.
We also placed the traditional CBS module with a GSConv structure. The GSConv module first takes an input and performs a regular convolution with downsampling. It then utilises DWConv (depthwise convolution) to further process the data. The results of both convolutions are concatenated together. Finally, a shuffle operation is applied to rearrange the corresponding channels from the previous two convolutions, placing them next to each other. In this way, the semantic information is protected effectively and the feature extraction ability of the model is improved.
Regarding the loss function, our model adopts the YOLO model’s approach. Therefore, we divide the losses into three categories: (1) classification loss; (2) bounding box loss; and (3) confidence loss.
In this paper, classification loss and confidence loss are presented by the binary cross entropy. SIoU loss is used for bounding box loss. Traditional loss functions, such as GIou, do not take into account the direction between the real frame and the predicted frame, resulting in slow convergence. For this purpose, SIoU introduces the vector Angle between the real box and the prediction box and redefines the relevant loss function. The loss includes four parts, Angle loss, distance loss, shape loss and IoU loss.
where σ is on behalf of the distance between the centre point of the real box and the prediction box, ch ia the height difference between the centre point of the real box and the predicted box, are the real box centre coordinates, bcx, bcy are the prediction box centre coordinates.
in this formula, .
where w, h are the width and height of the prediction box, respectively. θ is the degree of concern for shape loss. SIoU loss can be expressed as Eqn 18:
Results
Training
To evaluate the accuracy and effectiveness of the enhanced model, we utilised the PyTorch deep learning framework for model design and training. The trained model’s weights were then employed to predict forest flame and smoke images. The experiments were conducted using a GeForce RTX 4070 graphics card on the Windows 11 operating system. The details of our experiments are in Table 3.
| Experimental environments | Details | |
|---|---|---|
| Program Language | Python3.7 | |
| Deep learning frameworks | Pytorch | |
| Operating System | Windows 11 | |
| CPU | i7-13700KF | |
| GPU | NVIDIA GeForce RTX 4070 | |
| CUDA | Toolkit V11.7 | |
| Cudnn | 8.4.1 |
The experiments were trained on our mixed dataset. Considering the GPU memory size and the cost of time, we set the batch-size of the model to 8, initial learning rate to 0.01. According to the SGD optimiser, we adjusted the learning rate to set weight decay to 0.0005. Training parameters of our model were designed based on the YOLOV7 shown in Table 4. In our work, we considered using pre-trained weights to accelerate model convergence and reduce retraining costs. However, due to the extensive modifications, we made to both the backbone and neck networks, the pre-trained weights from YOLOV7 did not significantly enhance the training speed. Therefore, we chose to train our network from scratch. Additionally, while we explored other methods such as knowledge distillation, we found that the performance gains were minimal and it significantly increased inference time.
Comparison and evaluation
To analyse and demonstrate the early forest fire detection performance of our improved model, we employed the Microsoft COCO evaluation metrics. These metrics are widely used for evaluating object detection tasks and provide a comprehensive assessment of the model’s performance. Our model was trained on the training set and evaluated on the validation set. The main metrics used for evaluation are Average Precision (AP) and Average Recall (AR), which are calculated based on Precision (P) and Recall (R). The formulas for calculating AP and AR, derived from Precision and Recall, are presented in Eqns 19–22:
where TP, FP, and FN are true positive, false positive, and false negative, respectively. In Eqn (22), the o indexes the IoU between the prediction box and the ground truth box.
We compare our model with typical detectors. As seen in Table 5, we use AP, Precision and Recall for comparation. AP0.5 means average precision at IoU = 0.5. APs, APM, APL indicate the AP for small objects (area < 322), medium objects (322 < area < 962) and large ones (area > 962). To sum up, our model is superior in AP0.5, AP0.5:0.95, Precision, Recall and FPS compared with other typical detectors. Comprehensive improvements have been made for the model to acquire better performance in detecting flames and smoke against the background of a forest fire. The respective accuracy of flame and smoke in this experiment is in Table 6. It can be seen that compared with YOLOV7, the current model with the highest accuracy, our model has improved the accuracy of both flame and smoke. We also made ablation experiments to explore the reasonableness and effect of the proposed improvement in Table 5.
| Model | AP0.5 | AP0.5:0.95 | APS | APM | APL | Precision | Recall | Params/M | FPS | |
|---|---|---|---|---|---|---|---|---|---|---|
| SSD | 67.1 | 37.2 | 37.4 | 42.5 | 67.9 | 69.2 | 63.5 | – | 34 | |
| Faster R-CNN | 71.3 | 40.5 | 38.5 | 44.7 | 69.3 | 73.1 | 64.7 | – | 11 | |
| Yolov4 | 73.4 | 42.6 | 53.7 | 48.4 | 71.3 | 73.6 | 70.6 | 64.4 | 13 | |
| Yolov5 | 77.6 | 46.6 | 54.8 | 54.6 | 72.6 | 75.9 | 72.3 | 11.7 | 29 | |
| Efficient Det-D1 | 72.7 | 41.8 | 51.2 | 49.7 | 70.4 | 73.4 | 70.1 | 6.6 | 18 | |
| YOLOV7 (base line) | 78.4 | 50.3 | 56.1 | 58.7 | 73.8 | 76.8 | 72.6 | 37.6 | 23 | |
| +G-Retinex method | 79.5 | 50.9 | 58.2 | 60.3 | 73.4 | 77.1 | 72.8 | – | 23 | |
| +Flame segmentation | 80.1 | 51.2 | 58.6 | 61.7 | 73.9 | 77.5 | 73.1 | – | 23 | |
| +improved feature extraction backbone | 82.1 | 52.4 | 61.5 | 65.4 | 74.9 | 78.9 | 75.3 | – | 26 | |
| +ELAN-S neck | 82.9 | 52.8 | 62.1 | 66.8 | 75.1 | 79.3 | 75.9 | – | 27 | |
| +SIoU loss(ours) | 83.4 | 53.1 | 62.5 | 67.4 | 75.6 | 79.6 | 76.1 | 38.9 | 28 |
AP0.5, AP0.5:0.95, APS, APM, APL, Precision, and Recall are all percentages. Bold represents the model’s optimal value for a particular metric.
Detection performance and analysis
Extensive experiments have demonstrated the satisfactory performance of our model in early detection of forest flame and smoke. When compared to the well-regarded YOLOV7, one of the top detectors currently available, our model excels in addressing the issue of false detection of flame and smoke. The detection results depicted in Fig. 10 illustrate the effectiveness of our model. In Fig. 10a and b, our model effectively addresses the challenge of missing small target flame detection. Similarly, in images (c) and (d), our model overcomes issues related to the missed detection of some miniature flame targets. Thanks to the improved extracted backbone, our model exhibits a robust ability to detect flame spots in photos. Consequently, our introduced model proves valuable for the early detection of forest fire flame information.

In Fig. 10e and f, conventional detectors often overlook smoke that blends with the background. In contrast, our model adeptly captures such instances. Even for small smoke targets, our model not only detects them effectively but also demonstrates a high degree of confidence. In summary, the improved model proves highly effective in detecting flame and smoke across diverse backgrounds in forest fire scenarios.
Experimental results show that the detection speed of our model reaches 28 frames per second, which meets the requirements of real time monitoring. In the actual application of forest fire monitoring, the detection system can be deployed on the forest fire prevention watchtower, and the forest scene is captured by the monitoring equipment in the watchtower to realise the automatic monitoring of forest fire. In case of fire, timely alarm. Considering that the model size reaches 38.9 M, which is still larger and not suitable for deployment on small airborne devices, the model parameters can be reduced by pruning, quantisation, distillation, and other methods to facilitate deployment to edge devices. This research is in progress. It is important to emphasise that the computer vision model is an assistive technology to provide information assistance for forest fire rescue, helping relevant departments and personnel to take rapid response measures.
Results for smoke image, flame image, smoke flame mixed image and negative sample image are in Figs 11–14.




Discussion
Forest fire is a dynamic object and there are many factors at the visual level that impact on fire detection. In the real world scenario, with the start of small-scale fire, a forest fire is accompanied by smoke. Obscured by terrain and trees, sometimes flames are buried under shrubs, making smoke our primary detection target. However, on cloudy and foggy days, smoke is easily confused by the background. In this phenomenon, flame is our most recognisable feature.
In order to obtain fire information in different backgrounds, it is imperative to detect both flame and smoke. At the same time, the detection of small target flame and smoke is also the focus of our work. In the data processing phase, we introduce the G-Retinex method (Algorithm 1) to eliminate low image chroma while preserving edge information. Traditional method like SSR can hardly restore the edge information after processing. We combine the guide filter with Retinex method and have the perfect effect compared with other image processing methods. Based on the stability and significance of the flame colour, we segmented the flame in the YCbCr space. The segmented image is added to the training as the data after enhanced features. With these pre-processing method, the base model boost detection performance by 1.7% in terms of AP0.5 and improve the ability of different size of target by 2–2.5% in terms of APS, APM, and APL.
In feature extraction, the backbone of traditional convolutional neural networks is often generated by stacking a large number of convolutional blocks. This results in the extraction of redundant information and reduces the fitting speed. To address this issue, a feature extraction backbone mixed with DFC-C3ghost and C2f was designed. The ghost module does well in eliminate redundant information. Also, DFC attention mechanism and ghost module are mixed in channel, allowing for a more holistic representation. The cross-layer connection and residual structure in C2f can effectively alleviate the gradient dispersion phenomenon and improve the generalisation ability of the model. In the neck part, the add of ELAN-S introduces SimAM at the end of feature extraction. By extracting features from the structure of simulated brain neurons, SimAM improves the model’s receptive field of features. And the input features can be extracted better without introducing the number of parameters. Noticeably, the join of the improved backbone and ELAN-S raise detection performance by 4.5% in AP0.5. We divide the losses into three categories: (1) classification loss; (2) bounding box loss; and (3) confidence loss. Taking into account the direction between the real frame and the predicted frame, we adopt SIoU loss as the bounding box loss. Composed of Angle loss, distance loss, shape loss and IoU loss, SIoU optimises the performance of model inference to the extent. It helps boost the detection performance by 0.3–0.5% in terms of AP0.5, APS, APM, APL, Precision, and Recall.
However, our model still has some areas that require improvement. The simultaneous detection of flame and smoke is a complex task, as they do not possess complementary semantic information at the image level. Despite extracting features from high-dimensional data to detect fire and smoke, we are still constrained by the lack of pixel-level target information. The intricate forest environment and varying climatic seasons continue to present significant challenges for testing our models. Incorporating additional information such as spectral data and thermal maps can greatly enhance forest fire detection, and integrating computer vision with multi-scale information may facilitate the extraction of fire-related information, thus aiding in the early detection of forest fires.
Conclusion
As two important pieces of early fire detection smoke and flame have their advantages but in only considering flame or smoke detection fails to integrate the characteristics of both. In order to improve the early detection ability of forest fire targets, this paper proposes a forest fire detection model based on flame and smoke feature extraction. In terms of data processing, the G-Retinex method is introduced to enhance smoke information and retain edge information to eliminate the influence of forest background on smoke. At the same time, the YCbCr based flame segmentation is used to add flame data to improve the robustness and generalisation of the model. On the backbone network construction, the DFC-C3ghost module that combines ghost module and DFC attention is used to obtain stronger feature extraction ability. In addition, a more powerful neck network model is proposed, which adds the SimAM attention mechanism to improve the feature fusion ability of the neck network without introducing additional parameters. Considering the direction between the real frame and the predicted frame the SIoU loss is introduced as the bounding box loss to make the model have a stronger regression loss fitting ability.
Compared with other mainstream object detectors, our model achieves a better balance between detection speed and detection accuracy, which meets the needs of real-time monitoring. In forest fire monitoring, the model can be deployed on the monitoring system of the forest fire prevention watchtower to monitor forest fires in real-time.
Data availability
The data supporting this study will be shared on reasonable request sent to the corresponding author.
Declaration of funding
This research was funded by Postgraduate Research & Practice Innovation Program of Jiangsu Province (grant number KYCX22_1056) and National Key R&D Program of China (grant number 2017YFD0600904).
References
Appana DK, Islam R, Khan SA, et al. (2017) A video-based smoke detection using smoke flow pattern and spatial-temporal energy analyses for alarm systems. Information Sciences 418, 91-101.
| Crossref | Google Scholar |
Chen SJ, Hovde DC, Peterson KA, Marshall AW (2007) Fire detection using smoke and gas sensors. Fire Safety Journal 42, 507-515.
| Crossref | Google Scholar |
Chino DYT, Avalhais LPS, Rodrigues JF and Traina AJM (2015-October) Bowfire: Detection of fire in still images by integrating pixel color and texture analysis. In ‘Brazilian Symposium of Computer Graphic and Image Processing’. 10.1109/SIBGRAPI.2015.19
Dios JM-D, Arrue B, Ollero A, Merino L, Gómez-Rodríguez F (2008) Computer vision techniques for forest fire perception. Image and Vision Computing 26, 550-562.
| Crossref | Google Scholar |
Eugenio FC, dos Santos AR, Fiedler NC, Ribeiro GA, da Silva AG, dos Santos ÁB, Paneto GG, Schettino VR (2016) Applying GIS to develop a model for forest fire risk: a case study in Espírito Santo, Brazil. Journal of Environmental Management 173, 65-71.
| Crossref | Google Scholar | PubMed |
Fernandes AM, Utkin AB, Lavrov AV, Vilar RM (2004) Development of neural network committee machines for automatic forest fire detection using lidar. Pattern Recognition 37, 2039-2047.
| Crossref | Google Scholar |
Frizzi S, Kaabi R, Bouchouicha M, Ginoux JM, Moreau E, Fnaiech F (2016) Convolutional neural network for video fire and smoke detection. In ‘Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society’, 23–26 October 2016, Florence, Italy, pp. 877–882. 10.1109/IECON.2016.7793196
Hossain FA, Zhang YM, Tonima MA (2020) Forest fire flame and smoke detection from UAV-captured images using fire-specific color features and multi-color space local binary pattern. Journal of Unmanned Vehicle Systems 8, 285-309.
| Crossref | Google Scholar |
HPWREN Fire (2020) HPWREN Fire. Available at https://www.hpwren.ucsd.edu/FIgLib/ [accessed 18 August 2020]
Lee B, Kwon O, Jung C, Park S (2001) The development of UV/IR combination flame detector. Journal of KIIS 16, 1-8.
| Google Scholar |
Lu P, Zhao Y, Xu Y (2021) A two-stream CNN Model with adaptive adjustment of receptive field dedicated to flame region detection. Symmetry 13, 397.
| Crossref | Google Scholar |
Noda H, Niimi M (2007) Colorization in YCbCr color space and its application to JPEG images. Pattern Recognition 40(12), 3714-3720.
| Crossref | Google Scholar |
Pan J, Ou X, Xu L (2021) A collaborative region detection and grading framework for forest fire smoke using weakly supervised fine segmentation and lightweight faster-RCNN. Forests 12, 768.
| Crossref | Google Scholar |
Ryu J, Kwak D (2021) Flame detection using appearance-based pre-processing and convolutional neural network. Applied Sciences 11, 5138.
| Crossref | Google Scholar |
Töreyin BU, Dedeoğlu Y, Güdükbay U, Cetin AE (2006) Computer vision based method for real-time fire and flame detection. Pattern Recognition Letters 27, 49-58.
| Crossref | Google Scholar |
VisiFire:COMPUTER VISION BASED FIRE DETECTION SOFTWARE (2021) Available at http://signal.ee.bilkent.edu.tr/VisiFire/ [accessed 1 January 2021]
Yang Z, Bu L, Wang T, et al. (2020) Indoor video flame detection based on lightweight convolutional neural network. Pattern Recognition and Image Analysis 30, 551-564.
| Crossref | Google Scholar |
Ye S, Bai Z, Chen H, et al. (2017) An effective algorithm to detect both smoke and flame using color and wavelet analysis. Pattern Recognition and Image Analysis 27(1), 131-138.
| Crossref | Google Scholar |
Yu L, Wang N, Meng X (2005) Real-time forest fire detection with wireless sensor networks. In ‘Proceedings. 2005 International Conference on Wireless Communications, Networking and Mobile Computing’. Wuhan, China. pp. 1214–1217. 10.1109/WCNM.2005.1544272
Yuan C, Zhang Y, Liu Z (2015) A survey on technologies for automatic forest fire monitoring, detection, and fighting using unmanned aerial vehicles and remote sensing techniques. Canadian Journal of Forest Research 45, 783-792.
| Crossref | Google Scholar |