

A neural network model to study factors impacting the selection of hazardous fuel treatment types in Colorado’s national forests
Shayne Magstadt A * and Yu Wei AA
Abstract
Selecting suitable fuel treatment locations and types is important for reducing wildfire risks in Colorado’s national forests. Understanding factors influencing these decisions is needed for effective management.
This study analyses land management data from 2015 to 2024 using a single multiclass neural network model to understand the drivers influencing fuel treatment decisions in 11 Colorado national forests.
We utilise Forest Activity Tracking System data, incorporating variables such as wildfire risk, landscape features and human influences. The model employs a feed-forward backpropagation technique to train a neural network model on the spatial dataset.
The model identifies significant factors associated with past fuel treatment decisions, including burn probability, wildfire hazard potential, conditional flame length and proximity to structures. Analysis reveals the importance of these variables in shaping treatment selection strategies, the model AUC (area under curve) of 0.91 indicating strong predictive performance across the six treatment categories.
Neural networks provide a robust method for analysing past fuel treatment choices. Accurately identifying key factors, this approach provides suggestions to improve future fuel treatment decisions.
This approach can enhance wildfire mitigation planning across Colorado’s national forests. The findings support more informed wildfire mitigation strategies, with potential applications extending to broader forest management practices.
Keywords: artificial neural networks, Colorado national forests, data-driven decision making, geospatial analysis, hazardous fuel treatment, landscape analysis, machine learning, mechanical fuel treatment, prescribed fire, spatial data analysis.
Introduction
Colorado has experienced severe wildfires in recent years, causing significant damage to forests, communities and wildlife. For example, in 2020, Colorado experienced three of its largest wildfires on record, namely the Cameron Peak Fire, the East Troublesome Fire and the Pine Gulch Fire, which together burned over 540,000 acres (2185.3 square kilometers) (National Interagency Fire Center (NIFC) 2020). The economic impact of these wildfires has been immense, with recent studies estimating that wildfires in the western United States, including Colorado, have caused billions of dollars in direct damages and long-term economic losses, including property destruction, firefighting costs and loss of ecosystem services (Thomas et al. 2017). Given these substantial costs and the growing frequency of large wildfires, proactive measures are increasingly necessary. Landscape fuel treatments are needed to reduce the severity of future destructive wildfires. By reducing vegetation fuels, these treatments not only diminish the potential for extensive, damaging wildfires but also foster forest configurations that can enhance resilience and post-fire recovery. This approach potentially lessens the necessity for excessive firefighting efforts and may lead to lower fire suppression expenses (Reinhardt et al. 2008).
Hazardous fuel treatments (HFTs) are often classified into two main types, prescribed fire and mechanical treatment. Prescribed fires reduce surface fuels through combustion, whereas mechanical treatments reduce wildfire risk by changing the structure of forest fuels. Low-intensity surface fires are natural in many systems, and are critical in maintaining natural fire regimes and certain forest regeneration (Harmon 1984). Prescribed fires play similar roles to low-intensity surface fires and are often more cost-effective, but come with a higher risk of implementation due to the potential to escape their implementation boundaries and pose a risk to surrounding resources and communities (Fernandes and Botelho 2003). Moreover, prescribed fires require a strict set of weather conditions that may vary daily, limiting their implementation. Mechanical treatments manipulate the fuel continuity by altering vegetation biomass (Brennan and Keeley 2015). Several different types of mechanical treatments exist. For example, thinning removes vertical vegetation and reduces lateral forest fuel connectivity (Finney 2001). Yarding involves the removal of biomass from the landscape, whereas piling of fuels retains the biomass but rearranges it. Other important fuel treatment types commonly used in forested areas include mechanical mastication for crushing or chipping surface fuels (Agee and Skinner 2005), but because we did not find enough cases of those applications in our study area, we chose not to analyse them in this study. Although mechanical treatments carry less risk, they are more costly when implemented owing to the amount of labour and equipment required. Given funding and personnel constraints, forest management must prioritise restoration placement with suitable treatment types strategically to efficiently achieve landscape restoration goals (Barros et al. 2019).
Decisions for hazardous fuel treatments involve a multifaceted approach that integrates ecological, economic and social considerations. Science-based, quantitative guidelines for fuel management, particularly in dry forest ecosystems, are emphasised as important in recent research (Johnson et al. 2007). The need for a landscape-scale perspective in fuel management that iteratively assesses fire hazard, fuel treatments and wildfire behaviour to enhance ecological and social resilience to wildfires is also elaborated in a recent study (Hood et al. 2022). Others have advocated for a nuanced approach to fuel treatment, emphasising the need for treatments to be part of an integrated fire management strategy that addresses both ecological health and wildfire mitigation (Reinhardt et al. 2008). Using tools like the Fire and Fuels Extension of the Forest Vegetation Simulator (FFE-FVS) allows managers to simulate and evaluate the stand level effectiveness of various fuel treatment options in reducing fire hazard and improving forest structure over time (Reinhardt 2003). The Treatment Optimisation Model (TOM) identifies fuel treatment placement to minimise fire spread across the landscape (Finney 2006). Tools like ForSys can evaluate landscape scenarios to determine where to place restoration efforts to achieve multiple fuel management goals (Alcasena et al. 2018; Ager et al. 2021). Others have used modelling approaches aimed at optimising fuel treatment locations (Wei et al. 2008; Minas et al. 2015; Rachmawati et al. 2016; Matsypura et al. 2018). Ultimately, the placement of fuel treatments is based on a combination of management tools, funding resources, strategic planning, scientific research, risk assessments, and community and stakeholder engagement.
Machine learning (ML) has become an essential tool in the domain of wildfire risk management, particularly with the increased availability of high-level computing power (Jain et al. 2020). In the present study, we adopt the definition of ML as the automated detection of meaningful patterns in data (Shalev-Shwartz and Ben-David 2014). ML algorithms often focus on the accuracy of predictions and probabilities of a natural system (Carvalho et al. 2019), and can be used to gain useful insight into the connection between explanatory variables and the response variable (Kuhn and Johnson 2013).
One ML method used to observe the interaction between explanatory and response variables is the feed-forward artificial neural network (ANN). In its most basic form, an ANN consists of a neuron, which is designed to mimic the biological function of brain cells (Rosenblatt 1958). A neuron, often referred to as a perceptron, functions primarily as a linear regressor where the output is determined by calculating the dot product of inputs and weights plus a bias term. This value is then passed through a non-linear activation function, producing a continuous range of values. An ANN is a collection of combined perceptron units that act in parallel (Bishop 2006). In a feed-forward ANN, neurons from one layer transmit signals to all neurons in the next layer, with the network computing collective outputs through non-linear activation functions. There are numerous examples of efforts to use this ML method to understand various aspects of wildfire processes. For example, fire weather plays an important role in influencing fire spread; understanding it helps us design mitigation strategies. One research effort used meteorological factors to build an ANN model to predict the scale and magnitude of wildfires on a fire ignition (Liang et al. 2019). Studies have explored various neural network methods to predict wildfire occurrence (Alonso-Betanzos et al. 2003; Vasilakos et al. 2007; Sakr et al. 2011). For instance, a recurrent neural network was used to model the annual average area burned in Canada by utilising past wildfire risk to predict future landscape-scale burn area (Cheng and Wang 2008). Attempts using ANNs have also been made to map wildfire susceptibility and vulnerability using density of wildfire occurrence (De Vasconcelos et al. 2001; Bisquert et al. 2012; Jafari Goldarag et al. 2016; Adab 2017).
Although ANNs have been widely used in wildfire prediction and management, their application in studying hazardous fuel treatments has not been extensively explored. In our study, ANNs were leveraged to analyse and learn from historical fuel treatment data, gain insights into the factors associated with past hazardous fuel treatment strategies and provide suggestions to improve future hazardous fuel treatment allocation decisions. The dataset used in this study represents the outcomes of decisions made in multiple national forests over several decades in an evolving wildfire management system and reflects the spatial arrangement of the current fuel treatment strategy in national forests in Colorado. This study assesses past HFT locations and types based on both environmental and anthropogenic explanatory variables and evaluates the importance of these variables in explaining treatment decisions. Our findings from the analysis of historical fuel treatment decisions can help guide and enhance future treatment strategies in Colorado’s national forests.
Materials and methods
Study area
The study region encompasses a diverse 14.5-million-acre terrain across 11 national forests within Colorado, excluding the Manti–La Sal National Forest and the Comanche and Pawnee National Grasslands owing to insufficient data. To align with the US Forest Service administrative forest boundaries layer, which organises land by administrative units, we combined certain forests in our analysis. Specifically, the Arapaho and Roosevelt forests are grouped together, as are Grand Mesa, Uncompahgre and Gunnison, and Pike with San Isabel, owing to their ecological similarities and administrative proximity. This grouping resulted in seven distinct forest units used for our study (Fig. 1). The elevation of the study region spans from approximately 1700 to 3800 m, home to an array of forest types including conifer, mixed conifer–hardwood, aspen, lodgepole pine, piñon–juniper, ponderosa pine, spruce–fir and oak shrublands, as well as riparian zones. This area features a mosaic of rural landscapes punctuated by urban centres, with tree density and canopy cover showing marked variability influenced by a variety of factors such as altitude, species mix and the presence of water sources. This heterogeneity is further shaped by human activities like timber harvesting and natural disturbances such as wildfires and pest outbreaks. Our analytical timeframe spanned 2015 to 2024. The HFTs during this period were implemented across all national forests in Colorado in diverse ecosystems.
The administrative boundaries of the national forests in Colorado, highlighting the areas where hazardous fuel treatments have been implemented that are part of our study. The depicted black polygons represent the specific regions within these forests where fuel treatments have occurred from 2015 to 2024.
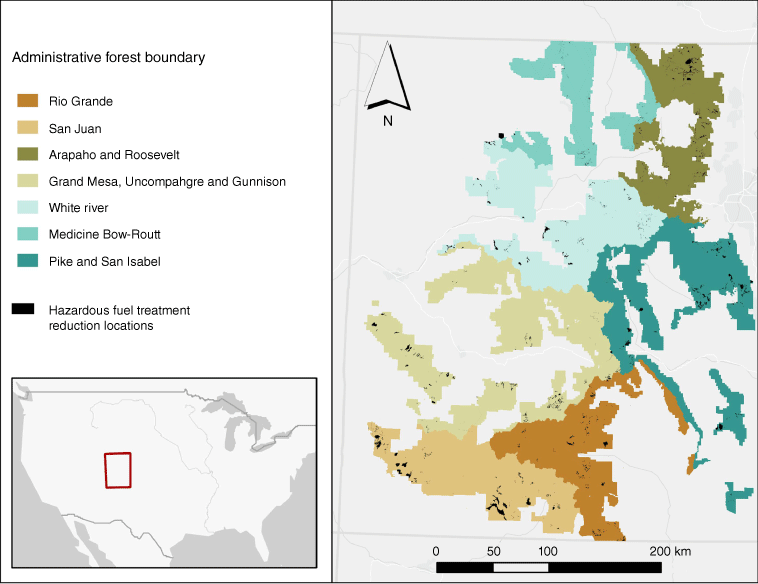
Hazardous fuel treatments
We sourced our historical HFT data from the georeferenced polygon dataset within the Forest Activity Tracking System (FACTS). This dataset comprises polygon locations of proposed HFTs across all US National Forests, reflecting the current treatment strategies adopted by the United States Forest Service (USFS). Our study was focused on Colorado, specifically utilising sites corresponding to fire risk reduction activities.
From the diverse range of different HFTs, we simplified our list of HFTs to include just six treatment classes. These included broadcast burning, which is the controlled application of fire to a predetermined area; burning of piled material, which involves setting fire to hazardous fuels previously accumulated either manually or mechanically; piling of fuels, a technique that entails collecting materials at a particular site; yarding, the act of extracting fuels from an area; and thinning for hazardous fuel reduction, a method that involves the selective cutting down of trees and shrubs for the exclusive purpose of fuel reduction. Piling of fuels is typically carried out as a preparatory treatment for prescribed fire but fuel often remains unburned in the study area, according to FACTS, likely owing to costs, liability associated with proximity to critical infrastructure and habitats, and concerns regarding smoke management near populated areas (Berry et al. 2006). Additionally, we introduced a multi-treatment category to account for areas that underwent more than one type of treatment, where at least one of the treatments was mechanical and one was either prescribed fire or burning of piled material during the analytical timeframe. Treatments that underwent multiple mechanical interventions but no application of any controlled burning were excluded from the dataset to maintain focus on areas where both types of treatment were applied. Although our primary analysis timeframe spanned from 2015 to 2024, the earliest of the treatments in the multi-treatment cases may be prior to this timeframe and can extend as far back as 2001.
In our dataset, some fuel treatment polygons overlapped, indicating areas that underwent multiple mechanical treatments over time in Colorado’s national forests. We selected only the most recent treatment from 2015 to 2024 for overlapping polygons, resulting in 6291 treatment units covering approximately 152,000 ha treated over an area of ~107,000 ha (Table 1). This approach avoided double counting the same area in our spatial analysis. Eight fuel treatment activities were omitted from our study owing to their limited sample size.
| Treatment | Sample area (ha) | |
|---|---|---|
| Broadcast burning | 42,232 | |
| Yarding | 6818 | |
| Burning of piled material | 14,105 | |
| Piling of fuels | 3749 | |
| Thinning for HFR | 4691 | |
| Multi-treatment | 27,501 |
It details the extent and distribution of various treatments within the study area, considering the possibility of repeated treatments in some locations.
Explanatory variables
An integral component of neural network modelling lies in curating a robust set of explanatory variables that correspond meaningfully with the response variable. For this purpose, we harnessed both vector and raster datasets, standardising each to a 30-m resolution squared grid. We also calculated the closest Euclidian distance from each landscape location to the closest roads, structures and water bodies. Broadly, the explanatory variables in our study can be compartmentalised into three predominant categories, which are wildfire risk, landscape and anthropogenic elements.
To capture fire-regime characteristics within the hazardous fuel treatment polygons, we employed LANDFIRE geospatial data. This multi-agency initiative strives to develop a uniform database of vegetation fuel metrics across the US (Rollins 2009). Metrics such as the Percentage of Replacement-severity Fire (PRS), Percentage of Mixed-severity Fire (PMS) and Percentage of Low-severity Fire (PLS) were used in gauging fire severity within historical fire regimes. PRS measures the percentage of an area within a fire perimeter where fire severity caused more than 75% average top-kill, indicating extensive vegetation damage and replacement post-fire. PMS quantifies the percentage of an area within a fire perimeter with moderate severity, causing 25–75% average top-kill, leading to a mixture of killed and surviving vegetation.
Spatial datasets of landscape-level wildfire risk factors were used to assess wildfire risk within treatment zones. This analysis integrated several key variables to quantify wildfire risk, including wildfire hazard potential (WHP) (Dillon and Gilbertson-Day 2020; Dillon et al. 2023) and flame length exceedance probability at 4 feet (1.2 meters) (FLEP4) and 8 feet (2.4 meters) (FLEP8) (Dillon et al. 2023). Additionally, we considered conditional risk to potential structures (CRPS) and conditional flame length (CFL), which are conditional on a fire occurring and represent the expected structure risk and flame length under such conditions (Dillon et al. 2014; Scott et al. 2020). We also considered burn probability (BP) (Dillon et al. 2023). BP is defined as the ratio of the number of times a cell is burned by a fire simulated by the FSim model to the total number of annual iterations simulated, and it serves as a quantitative measure for simulated wildfire exposure (Thompson and Calkin 2011). The proposed treatment data were extracted from the dataset version that most closely predated the analysed wildfire risk variables to ensure temporal consistency. These variables were used in evaluating the wildfire risk within each hazardous fuel treatment zone.
Our landscape characterisation incorporated spatial layers delineating slope (Slope), elevation (DEM) and proximity to water bodies (StreamEuc). For instance, terrains near water bodies predominantly feature riparian species, effectively excluding them as candidates for certain hazardous fuel treatment. Moreover, areas with steep inclines pose access challenges, and those at higher altitudes may offer limited value for treatment. Data on elevation, slope and water bodies were obtained from the USDA Geospatial Data Gateway (USDA-NRCS 2014).
Acknowledging that hazardous fuel treatments serve dual purposes, such as reducing wildfire severity and safeguarding human infrastructure, we introduced anthropogenic variables. These variables aimed to portray the intersection of HFT decisions with human-centric factors. We collected vector lines and points representing existing Forest Service roads and structures, available from the USFS FSGeoData Clearinghouse and USDA Geospatial Data Gateway respectively. These data were then transmuted into a 30-m resolution raster layer, with each cell representing its proximity to the closest road (RoadEuc) or structure (StrucEuc). Supplementary Table S1 provides a succinct summary of the descriptive statistics linked to the model’s explanatory variables.
Multicollinearity testing and variable selection
Multicollinearity poses challenges in modelling when several explanatory variables share a strong linear correlation, thereby obscuring their distinct impacts on the model (Mansfield and Helms 1982). Although it may not inherently compromise the predictive ability of a neural network, multicollinearity can introduce redundancies in the interpretive process (De Veaux and Ungar 1994). To identify and address potential collinearity in our dataset, we employed the variance inflation factor (VIF) as a diagnostic tool (Alin 2010). Conventionally, VIF values surpassing 10 demonstrate pronounced collinearity among explanatory variables. Conversely, values below 10 are generally indicative of negligible multicollinearity (Menard 2010). We omitted any explanatory variables with VIF values exceeding 10 (Vittinghoff et al. 2012). In our analysis, conducted using Python 3.7, we assessed multicollinearity among independent variables using the ‘variance_inflation_factor’ function from the ‘statsmodels.stats.outliers_influence’ module (statsmodels version: 0.14.0) (Seabold and Perktold 2010).
Feature normalisation
We addressed the challenge posed by the wide range of input variable values in the dataset by normalising the explanatory variables. Feature normalisation is a technique that transforms the independent variables to a common range, thereby ensuring equal weight is given to each explanatory variable (Nino-Adan et al. 2021). We used the Min–Max scaling algorithm, which scales the distribution of the data from the minimum and maximum values of the variables to 0 and 1, respectively (Patro and Sahu 2015). The transformation formula used for feature normalisation is shown here:
where z is the value after feature normalisation, xi is the value of the variable, min (xi) is the minimum value of the variable range, and max (xi) is the maximum value of the variable range. Feature normalisation was conducted on the training data after splitting the dataset into training and testing sets. The Min–Max scaling was then fitted on the training set and subsequently used to transform both the training and testing sets to maintain consistency. The feature normalisation was implemented in Python 3.7 using ‘scikit-learn’ (Feurer and Hutter 2019).
Hazardous fuel treatment model training
We designed our model based on a feed-forward ANN (Rosenblatt 1958). Given the complexity and non-linearity of large and varied datasets, ANNs are known for their proficiency in managing such data (Egmont-Petersen et al. 2002). More specifically, we chose a ’vanilla’ neural network architecture, which uses a feed-forward neural network trained using a backpropagation algorithm (Fig. 2). This algorithm optimises the network by adjusting weights and biases in response to errors, utilising gradient descent (Hecht-Nielsen 1992).
The model architecture of our feed-forward neural network with a single hidden layer. The network consists of an input layer with 9 neurons (denoted as X1, X2, …, X9), representing the input features, a hidden layer with 64 neurons (denoted as hi), and an output layer with 6 neurons (denoted as Y1, Y2, …, Y6), corresponding to the output predictions. Each neuron in one layer is fully connected to all neurons in the subsequent layer through weights (wi and wj), which are adjusted during the model training process.
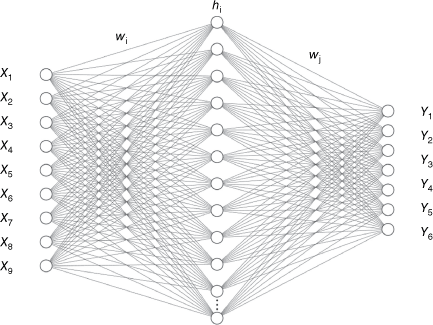
The training and validation of our model were based on a dataset encompassing 770,774 training samples and 330,331 validation samples (Table 2). The neural network architecture was chosen for its compatibility with the categorical input data and the range of explanatory variables involved in our study. The architecture, with its single hidden layer, was chosen to balance model complexity and predictive power, minimising the risk of overfitting and maintaining the ability to generalise effectively to unseen data (Goodfellow et al. 2016).
| National Forest | Hazardous fuel treatment | ||||||
|---|---|---|---|---|---|---|---|
| Broadcast burn | Yarding | Burning of piled material | Piling of fuels | Thinning For HFR | Multi-treatment | ||
| Rio Grande | 28,565 | 42,527 | 7129 | 114 | 1042 | 37,727 | |
| San Juan | 160,702 | 4256 | 14,964 | 30,789 | 331 | 47,206 | |
| Arapaho and Roosevelt | 36,932 | 3680 | 4794 | 6373 | 138 | 113,408 | |
| Grand Mesa, Uncompahgre and Gunnison | 65,877 | 1256 | 84,658 | 710 | 2444 | 18,081 | |
| White River | 110,727 | 23,862 | 4323 | 284 | 30 | 18,649 | |
| Medicine Bow–Routt | 2306 | 180 | 19,579 | 1 | 69 | 6361 | |
| Pike and San Isabel | 64,140 | 5 | 21,285 | 3387 | 48,074 | 64,140 | |
Each row represents a specific national forest, and columns denote different hazardous fuel treatment methods. The values in the table correspond to the number of pixels on the landscape, with each pixel representing a 30-m resolution.
To identify the most effective hyperparameters for our model, we utilised ‘KerasTuner’ with a random search strategy (Bergstra and Bengio 2012; O’Malley et al. 2019). This method facilitated an assessment of various node and activation function combinations to establish the model architecture. Our model was designed for a multiclass classification task, utilising the categorical cross-entropy loss function to optimise the model weights during training by measuring the discrepancy between the predicted probabilities and the actual class labels (Zhang and Sabuncu 2018). The Adam optimiser was selected for its computational efficiency and adaptability across varying model architectures (Kingma and Ba 2014). The output layer utilised the softmax activation function, providing a probability distribution across the predicted classes (Bishop 1995). The entire model was built using Python 3.7 and relied on the ‘Keras’ module, leveraging its high-level neural network application programming interface (API) for an efficient modelling process built on ‘TensorFlow’ (Abadi et al. 2015; Chollet 2021).
Evaluation of model performance
For this study, we aimed to predict six distinct types of HFTs. To gauge our model’s robustness, we utilised the receiver operating characteristic (ROC) curve, deriving the area under the curve (AUC). We employed a 10-fold cross-validation approach to provide a more comprehensive assessment of the model’s performance across different data subsets. The AUC was not only applied in a macro context but was also measured for each fuel treatment type in contrast to the other classes (Woods and Bowyer 1997; Jiménez-Valverde 2012; Guo et al. 2017). To calculate the AUC for each class, we employed a one-vs-all approach. This method involves treating each class as the positive class and combining all other classes as the negative class, and then calculating the AUC for each scenario. For example, in the case of broadcast burning, we calculated its AUC by considering it as the positive class and all other treatment methods as the negative class. This process was repeated for each class, allowing us to assess the model’s performance for individual classes in addition to the overall performance. We computed the AUC using the ‘roc_auc_score’ function from the ‘sklearn.metrics’ module (scikit-learn version: 1.2.2) in Python 3.7 (Pedregosa et al. 2011).
Feature significance
We used permutation importance analysis to evaluate the significance of each feature in our ML model (Altmann et al. 2010). This approach involves shuffling the values of individual features and observing the subsequent changes in model performance. The resulting feature importance metrics offered transparency on the relative significance of each feature within the model’s predictions. The permutation importance analysis was implemented using the ‘eli5’ Python module (eli5 version: 0.13.0). Then, using the ‘sklearn.inspection’ module (scikit-learn version 1.2.2), we generated partial dependence plots (PDPs) for explanatory variables to illustrate how individual variables influence the model’s predictions for each response variable while holding other factors constant (Pedregosa et al. 2011). These plots reveal the marginal impact of each variable on the likelihood of the target outcome. Through these visual representations, we cite both the nature and the strength of the relationships between explanatory variables and the target.
To mitigate the influence of spatial autocorrelation when modelling hazardous fuel treatments across various national forests, we implemented a leave-one-out cross-validation (LOOCV) method (Kuhn and Johnson 2013). In this method, data from each national forest were segregated into a single test set with the remaining forests’ data used for training. This procedure was repeated until each forest had been used as a test set, ensuring the model’s evaluation reflected its effectiveness in predicting across separate geographical areas without the confounding effects of spatial dependencies. The application of the LOOCV method in this study was used to evaluate the generalisability of models designed to predict wildfire management practices across a diverse range of national forests.
We compiled a comprehensive dataset covering the 11 national forests in Colorado, intending to assess our model’s fit across these areas. To ensure the applicability of our model fitting, we implemented a filtering process based on the historical dataset used to train the model. Specifically, we compared each variable in the comprehensive national forests’ dataset against the corresponding minimum and maximum values found in our training dataset. This maintained consistency between the training and fitting conditions of the model. By enforcing this range-based filtering, we aimed to eliminate any areas within the national forests dataset that exhibited extreme values not represented in our training data, thus focusing the model’s predictions on regions with similar characteristics to those observed when building the model (Cao and Yousefzadeh 2023).
Finally, we fitted the model to this refined dataset, enabling us to examine the predictive dynamics within the ranges historically observed. We treated the model’s predicted values as probabilistic estimates, each informing the parameters of probability distributions for the respective response variables. This methodology allowed us to capture and represent the inherent uncertainty and variability in the predictions. We modelled the outcomes using a multinomial distribution, which reflects the diversity of potential values each response variable could assume based on the model’s forecasts.
Results
The results of the VIF calculation for each explanatory variable are reported in the Supplementary Table S2. Owing to high levels of multicollinearity, the variables FLEP4, CRPS, PRS, PMS, PLS were removed from the modelling dataset. Therefore, the modeling dataset consisted of the HFT label and nine explanatory variables: WHP, CFL, FLEP8, BP, StreamEuc, Slope, DEM, RoadEuc, and StrucEuc.
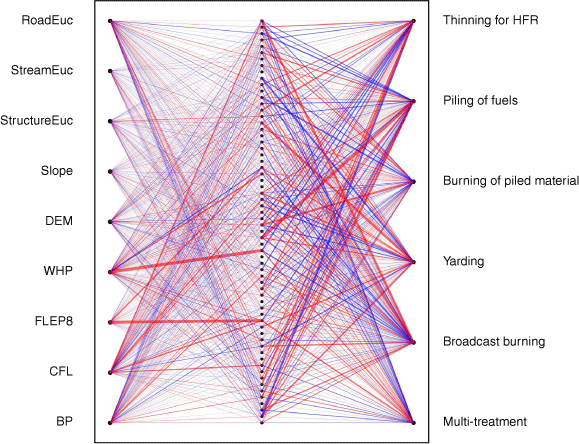
Our predictive model’s architecture, selected through a randomised grid search, consists of a single hidden layer with 64 neurons using rectified linear unit (ReLU) activation. We trained the model over 10 epochs, fine-tuning the model weights with a learning rate of 0.001, employing the Adam optimiser and categorical cross-entropy as the loss function. The final model weights are visualised to provide a representation of the weight adjustments after the training process (Fig. 3). The largest magnitude negative weight in the hidden layer is −15.2, connecting the input ‘WHP’ to hidden node 27, whereas the largest positive weight is 4.96, connecting ‘WHP’ to hidden node 40. In the output layer, the largest magnitude negative weight is −11.54, linking hidden node 29 to the output class ‘piling of fuels’, and the largest positive weight is 7.33, connecting hidden node 1 to the output class ‘thinning for HFR’.
A neural network weight visualisation representing the connections and their significance between input features and outputs in a three-layer ANN. The input features include ‘WHP’, ‘DEM’, ‘CFL’, ‘FLEP8’, ‘BP’, ‘StreamEuc’, ‘Slope’, ‘RoadEuc’, ‘StrucEuc’. Connections from input features to subsequent layers are depicted with lines, where the thickness indicates the weight magnitude and the colour represents the weight sign (blue for positive weights, red for negative weights).
After preparing the dataset and adapting it for our model, performance evaluation was conducted using distinct testing datasets. Our results yielded a macro-average AUC of 0.91 ± 0.0269 for the testing datasets. Among the classes, broadcast burning and thinning for HFR achieved the highest AUC score at 0.945 and 0.947 respectively, whereas the multi-treatment category had the lowest AUC score at 0.866 (Table 3).
| Prediction class | Testing AUC | |
|---|---|---|
| Broadcast burning | 0.945 ± 0.0003 | |
| Yarding | 0.922 ± 0.0007 | |
| Burning of piled material | 0.910 ± 0.0006 | |
| Piling of fuels | 0.922 ± 0.0010 | |
| Thinning for HFR | 0.947 ± 0.0011 | |
| Multi-treatment | 0.866 ± 0.0008 |
The AUC scores represent the model’s discriminative ability for each treatment class against the rest, with corresponding standard errors derived from bootstrap resampling to quantify the estimate’s precision.
Our permutation analysis highlights the significance of each feature within the model, revealing their order of importance. The most influential features, in descending order, are DEM, CFL, WHP, BP, FLEP8, StrucEuc, RoadEuc, Slope and StreamEuc (Table 4). DEM and CFL stood out with mean importance values of 0.221 and 0.171, indicating a notable decrease in performance when permuted. This was followed by WHP and BP, which showed mean importance values of 0.144 and 0.132. Slope and StreamEuc showed the lowest importance values of 0.0384 and 0.0345, respectively.
| Variable | Importance | s.d. | |
|---|---|---|---|
| DEM | 0.222 | 0.0007 | |
| CFL | 0.717 | 0.0007 | |
| WHP | 0.144 | 0.0005 | |
| BP | 0.132 | 0.0003 | |
| FLEP8 | 0.131 | 0.0004 | |
| StrucEuc | 0.0826 | 0.0004 | |
| RoadEuc | 0.0467 | 0.0004 | |
| Slope | 0.0384 | 0.0004 | |
| StreamEuc | 0.0345 | 0.0004 |
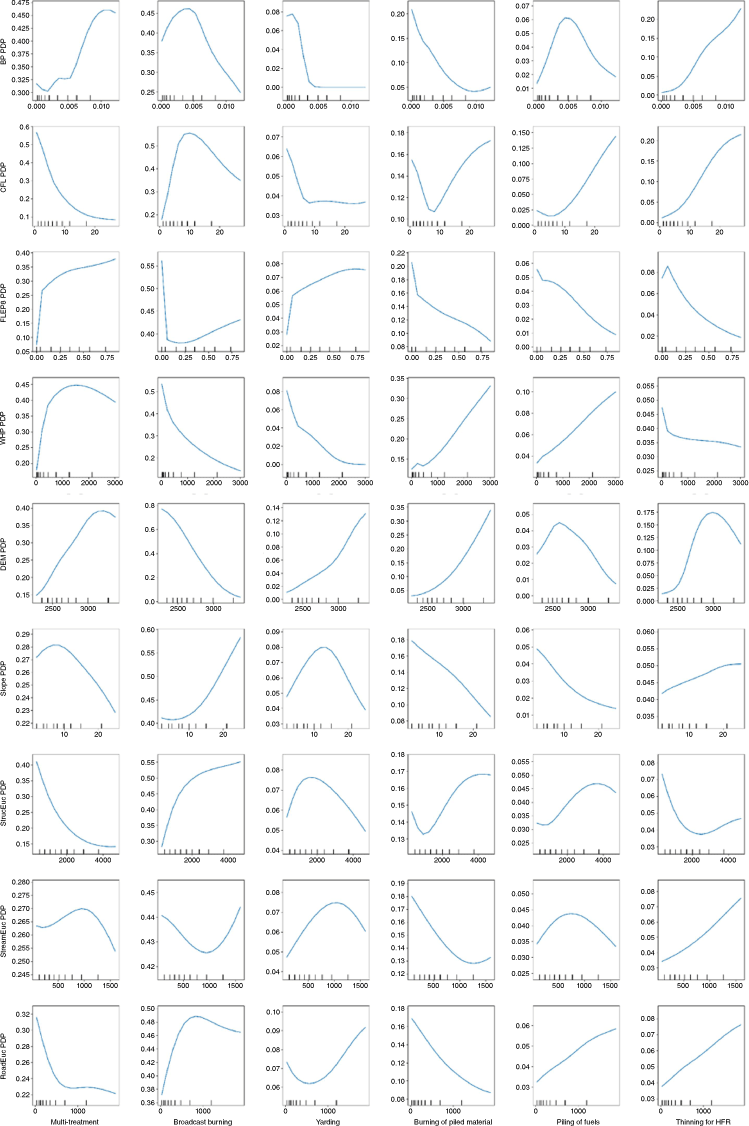
The likelihood of broadcast burning increases in areas with lower BP and WHP values, which are typically regions with reduced wildfire risk (Fig. 4). Burning of piled material is more likely to occur in higher-elevation areas with lower BP values and closer to roads, i.e. regions with a lower baseline probability of burning but near roads. Broadcast burning is predicted to be more frequent in remote areas at greater distances from structures and lower elevation. Piling of fuels is more expected in areas with greater CLF and higher WHP values where fuels are more likely to be piled as a preparatory step for future treatments such as burning. Thinning for hazardous fuel reduction is more likely in areas with a higher baseline probability of burning (BP) and greater flame length (CFL). The model also shows a higher likelihood of predicting multi-treatment approaches near structures, roads, and where CLF is lower.
Partial dependence plots illustrate the influence of explanatory variables on different forest treatment activities. The plots depict the relationship between each explanatory variable and the following treatment activities: broadcast burning, yarding, burning of piled material, piling of fuels, thinning for HFT and multi-treatment.
The LOOCV scores varied notably across different national forests, indicating the differential predictive power of the model in various forest environments (Supplementary Table S3). For instance, the model showed high predictive accuracy in the broadcast burning category in the Rio Grande NF, with a score of 0.928. The model also performed well for broadcast burning in the Medicine Bow–Routt NF, with an AUC of 0.923. This suggests the model is highly effective in predicting the implementation of this practice in these specific national forests. Conversely, the lower scores observed in the practice like burning of piled material in Pike and San Isabel NF point to a reduced predictive accuracy of the model for these practices in these environments.
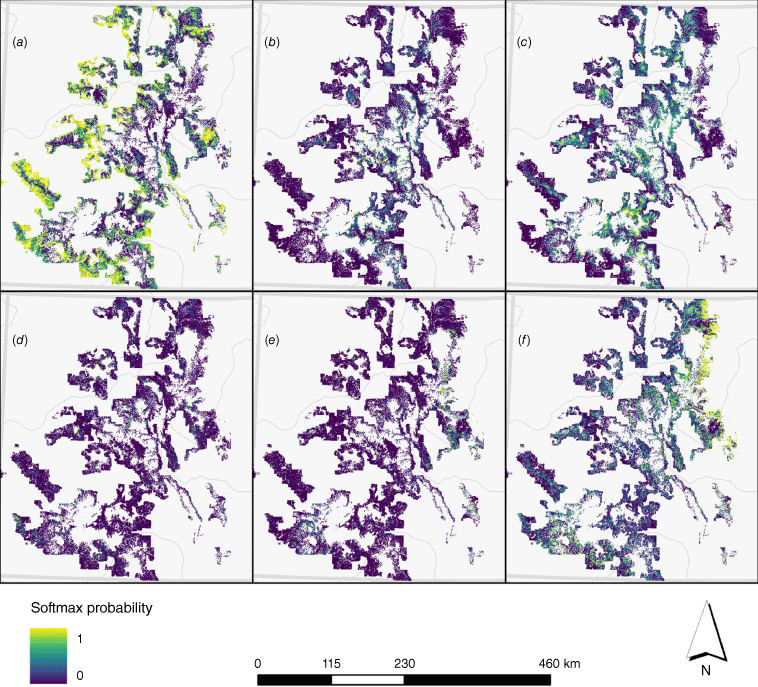
By removing regions falling outside the historical range of all considered explanatory variables, 45.2% of the total area within Colorado’s national forests was excluded from the model inference (Fig. 5). The exclusion criteria particularly impacted regions with extreme topographical features such as very high mountain peaks, steep slopes, or at considerable distance from structures. This filtration step eliminated zones presumably beyond the scope of historical fuel treatment implementation. The model consistently predicted broadcast burning with higher frequency in the largely rural and less densely populated areas of the Colorado Western Slope. However, the more urbanised Eastern Slope exhibited a greater likelihood of the multi-treatment category. This highlights the model’s ability to capture regional variations in fuel treatment strategies based on population density and land use.
Map of softmax probability outputs generated from model prediction across 11 national forests in Colorado: (a) broadcast burning, (b) yarding, (c) burning of piled material, (d) piling of fuels, (e) thinning for HFT, (f) multi-treatment.
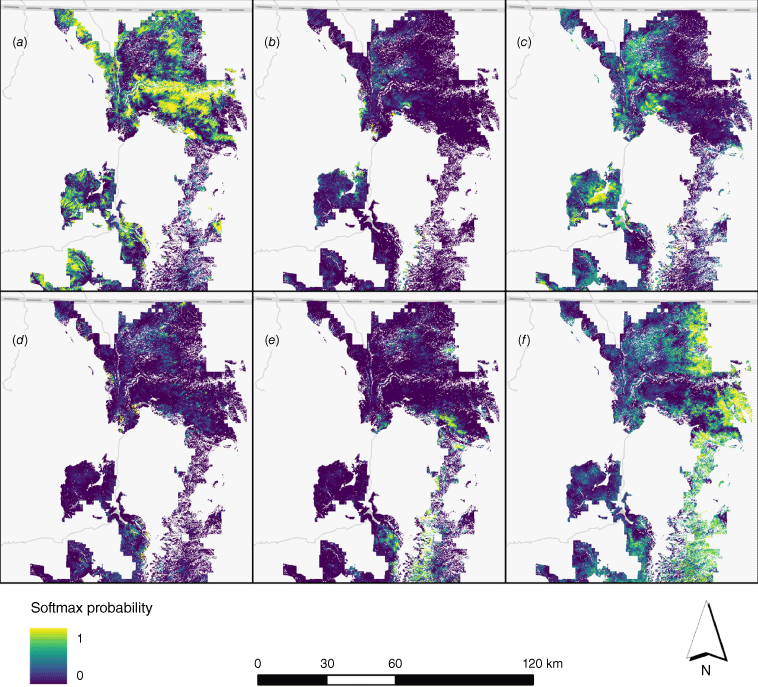
Additionally, the model’s fine-resolution capabilities provided detailed, spatially explicit predictions for six primary treatments within the Arapaho–Roosevelt National Forest, showcasing its effectiveness in modelling complex landscapes and diverse treatment strategies (Fig. 6). A notable trend is the model’s prediction of a higher frequency of the multi-treatment category proximate to the Colorado Front Range. There is a discernible prediction pattern for prescribed burning in the northern areas of this forest, which is distinguished by its rural characteristics and lower housing density.
Discussion
The primary aim of this study was to leverage spatial data and artificial neural networks to analyse past HFT decisions in Colorado’s national forests. Despite ANNs being recognised as valuable tools in fire management, their utilisation in modelling spatially explicit treatments remained less explored (Jain et al. 2020). The present study marks the first application of neural network modelling utilising past fuel treatment type selections as response variables, and notably, represents the first attempt at integrating human decision-making processes into a deep learning model for fuel treatment management.
Our study uses a historical analysis approach to study the nuanced operational considerations and human knowledge that land managers used to assign fuel treatment placement in the past. These treatment decisions often encapsulate expertise and understanding of the local ecological and operational dynamics. The variables considered in this study reflect both the specific objectives managers seek to address – such as reducing wildfire risk by enhancing forest health – and the operational constraints they face. This approach emphasises the value of empirical research in real-world settings (Thompson and Calkin 2011). The significance of this research lies in its ability to link data with historical treatment decisions in Colorado, offering an assessment of the key factors that influence past forest fuel treatment decisions. Using past management decisions as a reference provides a practical framework for understanding the choices and constraints that shaped treatment decisions.
This research introduces a modelling approach that leverages historical land management decisions to create labelled data for assessing fuel treatments using an ANN. The creation of labelled data in this research relies on historical fuel treatment decisions, which are presumed to have been made with the intent of reducing wildfire risk. The success of these treatments is subjective and varies based on the objectives of different stakeholders (Reinhardt et al. 2008). Given the constraints inherent in the available dataset, our modelling efforts were focused on operational conditions rather than attempting to assess treatment or policy success. Although we were unable to conclusively determine if the treatment placements maximised objectives, this dataset represents a comprehensive resource for examining historical fuel treatment management practices spatially in Colorado. It is reasonable to infer that these decisions were not made arbitrarily and were influenced by underlying strategic considerations and practical feasibility. Therefore, we chose to utilise this dataset to understand past decisions and to investigate the relationship between treatment locations and our explanatory variables.
We examined the individual effects of each variable within the model using permutation importance (Rodrigues and De la Riva 2014; Kalantar et al. 2020; Pham et al. 2020). The high importance of burn probability and wildfire hazard potential and their inverse relationship with the likelihood of broadcast burning underscore a strategic choice in the past for reducing wildfire impacts through prescribed fires in lower-risk areas, potentially as a measure to maintain low fuel loads rather than reducing high fuel loads. Conversely, the partial dependence plot reveals a strategic approach where thinning is more likely to be implemented in areas with higher BP and CFL values, suggesting that in national forests in Colorado, the current strategy favours prescribed fires in less vulnerable areas while prioritising thinning practices in overstocked forests requiring urgent restoration interventions to mitigate wildfire risk (US Department of Agriculture 2022).
The PDP plot revealed that the likelihood of the model predicting multi-treatment categories decreased as the distance from structures increased, suggesting an operational constraint that favours implementing multiple forms of treatments closer to the wildland–urban interface (WUI). Additionally, the analysis of variable influence using partial dependency implies that broadcast burning was more likely to be prescribed further from structures, aligning with the management strategy of conducting such burns in regions with sparse populations and lower structural density (Addington et al. 2020). This approach indicates that Colorado’s current management chooses prescribed burns in less populated areas for wildfire hazard management while operational constraints drive the use of multi-treatments near infrastructure to minimise risks. Given that the WUI in the Colorado Front Range corridor is projected to shift to higher elevations in the future (Liu et al. 2015), the DEM variable becomes increasingly important to examine. Fig. 4 suggests the multi-treatment categories are more likely to be prescribed in higher-elevation forest types, indicating that the system could adapt to future WUI changes, allowing the continued implementation of diverse treatment strategies as urban areas expand into higher elevations. As nearly half of the WUI in the United States is in regions with high wildfire severity potential that historically experienced lower-severity fires (Theobald and Romme 2007), this approach addresses the increasing fire risks as urban development expands into new landscapes.
WHP uses modelled probabilistic wildfire risk components to map areas where high-intensity wildfires may be difficult to manage and where fuel management may be needed (Dillon et al. 2014). The trend of decreased prediction of broadcast burning as WHP increases indicates the current management strategy favours concentrating prescribed burns in areas with lower wildfire hazard potential. Liability concerns are often noted as a significant barrier to the use of prescribed fire, particularly due to fears of legal repercussions if a fire escapes (Weir et al. 2019). Despite the empirical risk of liability from escaped fires being minimal (below 1%), the fear of legal consequences persists, often exacerbated by sensational media coverage and a lack of accurate information about the safety and benefits of prescribed fire. If the current management strategies do not change, we can expect prescribed fires to continue being conducted primarily in areas where the wildfire risk is already low.
The greater housing density adjacent to the urban Colorado Front Range presents unique challenges and considerations for wildfire management (Haas et al. 2015). Consequently, results suggest the need of considering a multi-treatment strategy at the complex urban–forest interface on the eastern slope of Colorado, indicating that diverse management approaches may contribute to effectively balancing wildfire risk reduction and urban protection (Figs 5 and 6). This approach inherently aligns with recent planning efforts in the Arapaho and Roosevelt National Forests and Pawnee National Grassland (US Department of Agriculture 2023). By combining mechanical treatments with prescribed burns, forest conditions can be effectively restored and ecosystem function enhanced (Kalies and Kent 2016). This integrated approach is highlighted in the Wildfire Crisis Strategy, which emphasises the critical role of managing fuel loads and mitigating wildfire risks, particularly in fire-adapted landscapes where ecological and community safety priorities intersect (US Department of Agriculture 2022).
Land management decisions regarding fuel treatments have been significantly influenced by policies aimed at addressing the accumulation of forest fuels. This build-up is largely due to extended periods of fire suppression, prolonged droughts and the escalation of disease, and insects and invasive plant infestations. In response, the National Fire Plan was established in 2000, initiating a comprehensive, long-term hazardous fuels reduction program (USDA–USDI 2000). Further supporting these efforts, the Healthy Forests Initiative and the Healthy Forests Restoration Act have provided land managers with additional tools to achieve their long-term objectives in reducing hazardous fuels and restoring fire-adapted ecosystems (US Congress 2003). More recently, the Bipartisan Infrastructure Law provides funding support and policy guidance in Colorado to increase fuel treatments in regions with high wildfire hazard potential (US Congress 2021). The underlying considerations of these policies provide essential guidance and resources for managing forest fuels in the future; yet the ultimate decision-making process integrates these policy frameworks with the expertise of local land managers. This combination ensures that land management actions are not only aligned with national objectives but are also adapted to the specific ecological and operational realities of their respective regions. By integrating these policy frameworks with practical insights from our analysis, land managers can make more informed decisions about fuel treatment strategies that consider both historical data and current ecological and operational realities.
This model helps identify key factors associated with the choice of fuel treatment types implemented across the Colorado national forest landscape. Although our study focuses on understanding factors linked to past fuel treatment decisions, validating the effectiveness of different fuel treatment types across a diverse landscape is another important subject to study in future research. This analysis can help managers deliberately consider a minimum set of factors when selecting future fuel treatment strategies. For example, when selecting the suitable locations for broadcast burning, managers should at least analyse the following factors: conditional flame length, burn probability, wildfire hazard potential and distance to nearby buildings. More importantly, managers may want to reflect on the underlying reasons why those factors are important considerations for broadcast burning. For example, distance to nearby buildings may be less important if there are clear fire barriers between a building and a candidate prescribed burning site. It is also important to note that the factors tested in our model mainly focused on wildfire risk and anthropogenic considerations and did not encompass all potential variables. For example, certain vegetation characteristics in a specific location can influence treatment placement and treatment type selections. Future studies could employ higher temporal resolution satellite imagery or other forms of remotely sensed data such as LiDAR to better capture dynamic changes in vegetation structure and density. Managers may need to include some other restrictions, e.g. no mechanical treatment in certain wilderness areas, to determine suitable fuel treatment locations and types.
By analysing historical trends, we aim to create a foundation for refining and informing future management strategies. These results can identify additional locations beyond historically treated areas and potential treatment types for hazardous fuel treatments. Furthermore, this approach serves as a diagnostic tool, refining future management decisions by recognising patterns of risk related to where treatments are implemented. Additionally, this model can facilitate better communication and collaboration among stakeholders by providing a transparent, data-driven approach to wildfire management. Given that over three-quarters of the public support active management strategies, such as prescribed fire and mechanical thinning, recognising their importance over no management action (Agee 2002), we must continue to develop strategies and solutions to improve the decision-making process.
Data availability
All data supporting the findings of this study are available within the article and its supplementary materials. The data are derived from publicly accessible databases and no proprietary restrictions apply. Details of the open-source datasets used are provided in the manuscript.
Declaration of funding
This research was supported by the Agricultural Experiment Station McIntire Stennis Funding from Colorado State University (CSU), grant number COL00516. The funding source was not involved in the preparation of the data, the manuscript or the decision to submit for publication.
Acknowledgements
We thank Alex Arkowitz for his valuable feedback on the manuscript and Benjamin Gannon for his assistance with the conceptual aspects of the model. This manuscript was enhanced based on feedback from three anonymous reviewers and multiple internal reviewers. The content of this manuscript is solely the responsibility of the authors and does not represent the official views of the CSU Agricultural Experiment Station.
References
Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, Corrado GS, Davis A, Dean J, Devin M, Ghemawat S, Goodfellow I, Harp A, Irving G, Isard M, Jia Y, Jozefowicz R, Kaiser L, Kudlur M, Levenberg J, Mané D, Monga R, Moore S, Murray D, Olah C, Schuster M, Shlens J, Steiner B, Sutskever I, Talwar K, Tucker P, Vanhoucke V, Vasudevan V, Viégas F, Vinyals O, Warden P, Wattenberg M, Wicke M, Yu Y, Zheng X (2015) TensorFlow: large-scale machine learning on heterogeneous systems. (Google Brain) Available at https://www.tensorflow.org/
Adab H (2017) Landfire hazard assessment in the Caspian Hyrcanian forest ecoregion with the long-term MODIS active fire data. Natural Hazards 87, 1807-1825.
| Crossref | Google Scholar |
Addington RN, Tavernia BG, Caggiano MD, Thompson MP, Lawhon JD, Sanderson JS (2020) Identifying opportunities for the use of broadcast prescribed fire on Colorado’s Front Range. Forest Ecology and Management 458, 117655.
| Crossref | Google Scholar |
Agee JK (2002) The fallacy of passive management managing for firesafe forest reserves. Conservation in Practice 3(1), 18-26.
| Crossref | Google Scholar |
Agee JK, Skinner CN (2005) Basic principles of forest fuel reduction treatments. Forest Ecology and Management 211(1–2), 83-96.
| Crossref | Google Scholar |
Ager AA, Evers CR, Day MA, Alcasena FJ, Houtman R (2021) Planning for future fire: scenario analysis of an accelerated fuel reduction plan for the western United States. Landscape and Urban Planning 215, 104212.
| Crossref | Google Scholar |
Alcasena FJ, Ager AA, Salis M, Day MA, Vega-Garcia C (2018) Optimizing prescribed fire allocation for managing fire risk in central Catalonia. Science of The Total Environment 621, 872-885.
| Crossref | Google Scholar | PubMed |
Alin A (2010) Multicollinearity. Wiley Interdisciplinary Reviews: Computational Statistics 2(3), 370-374.
| Crossref | Google Scholar |
Alonso-Betanzos A, Fontenla-Romero O, Guijarro-Berdiñas B, Hernández-Pereira E, Andrade MIP, Jiménez E, Soto JLL, Carballas T (2003) An intelligent system for forest fire risk prediction and firefighting management in Galicia. Expert Systems with Applications 25(4), 545-554.
| Crossref | Google Scholar |
Altmann A, Toloşi L, Sander O, Lengauer T (2010) Permutation importance: a corrected feature importance measure. Bioinformatics 26(10), 1340-1347.
| Crossref | Google Scholar | PubMed |
Barros AM, Ager A, Day M, Palaiologou P (2019) Improving long-term fuel treatment effectiveness in the National Forest System through quantitative prioritization. Forest Ecology and Management 433, 514-527.
| Crossref | Google Scholar |
Bergstra J, Bengio Y (2012) Random search for hyper-parameter optimization. Journal of Machine Learning Research 13(2), 281-305.
| Google Scholar |
Berry AH, Donovan G, Hesseln H (2006) Prescribed burning costs and the WUI: economic effects in the Pacific Northwest. Western Journal of Applied Forestry 21(2), 72-78.
| Crossref | Google Scholar |
Bisquert M, Caselles E, Sánchez JM, Caselles V (2012) Application of artificial neural networks and logistic regression to the prediction of forest fire danger in Galicia using MODIS data. International Journal of Wildland Fire 21(8), 1025-1029.
| Crossref | Google Scholar |
Brennan TJ, Keeley JE (2015) Effect of mastication and other mechanical treatments on fuel structure in chaparral. International Journal of Wildland Fire 24(7), 949-963.
| Crossref | Google Scholar |
Cao X, Yousefzadeh R (2023) Extrapolation and AI transparency: why machine learning models should reveal when they make decisions beyond their training. Big Data & Society 10(1), 20539517231169731.
| Crossref | Google Scholar |
Carvalho DV, Pereira EM, Cardoso JS (2019) Machine learning interpretability: a survey on methods and metrics. Electronics 8(8), 832.
| Crossref | Google Scholar |
Cheng T, Wang J (2008) Integrated spatio-temporal data mining for forest fire prediction. Transactions in GIS 12(5), 591-611.
| Google Scholar |
De Vasconcelos MP, Silva S, Tome M, Alvim M, Pereira JC (2001) Spatial prediction of fire ignition probabilities: comparing logistic regression and neural networks. Photogrammetric Engineering and Remote Sensing 67(1), 73-81.
| Google Scholar |
Dillon GK, Gilbertson-Day JW (2020) Wildfire Hazard Potential for the United States (270-m), version 2020. 3rd Edition. (Forest Service Research Data Archive: Fort Collins, CO) 10.2737/RDS-2015-0047-3
Dillon GK, Scott JH, Jaffe MR, Olszewski JH, Vogler KC, Finney MA, Short KC, Riley KL, Grenfell IC, Jolly MW, Brittain S (2023) ‘Spatial datasets of probabilistic wildfire risk components for the United States (270m).’ (Forest Service Research Data Archive) 10.2737/RDS-2016-0034-3
Egmont-Petersen M, de Ridder D, Handels H (2002) Image processing with neural networks—a review. Pattern Recognition 35(10), 2279-2301.
| Crossref | Google Scholar |
Fernandes PM, Botelho HS (2003) A review of prescribed burning effectiveness in fire hazard reduction. International Journal of Wildland Fire 12(2), 117-128.
| Crossref | Google Scholar |
Finney MA (2001) Design of regular landscape fuel treatment patterns for modifying fire growth and behavior. Forest Science 47(2), 219-228.
| Crossref | Google Scholar |
Finney MA (2006) An overview of FlamMap fire modeling capabilities. In ‘Fuels management – how to measure success: Conference Proceedings RMRS-P-41’, 28-30 March 2006; Portland, OR. (Eds PL Andrews, BW Butler, comps) pp. 213–220. (US Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO)
Guo C, Pleiss G, Sun Y, Weinberger KQ (2017) On calibration of modern neural networks. In ‘International conference on machine learning. Proceedings of Machine Learning Research 70:1321-1330. Available at https://proceedings.mlr.press/v70/guo17a.html
Haas JR, Calkin DE, Thompson MP (2015) Wildfire risk transmission in the Colorado Front Range, USA. Risk Analysis 35(2), 226-240.
| Crossref | Google Scholar | PubMed |
Harmon ME (1984) Survival of trees after low-intensity surface fires in Great Smoky Mountains National Park. Ecology 65(3), 796-802.
| Crossref | Google Scholar |
Hood SM, Varner JM, Jain TB, Kane JM (2022) A framework for quantifying forest wildfire hazard and fuel treatment effectiveness from stands to landscapes. Fire Ecology 18(1), 33.
| Crossref | Google Scholar |
Jafari Goldarag Y, Mohammadzadeh A, Ardakani A (2016) Fire risk assessment using neural network and logistic regression. Journal of the Indian Society of Remote Sensing 44(6), 885-894.
| Crossref | Google Scholar |
Jain P, Coogan SC, Subramanian SG, Crowley M, Taylor S, Flannigan MD (2020) A review of machine learning applications in wildfire science and management. Environmental Reviews 28(4), 478-505.
| Crossref | Google Scholar |
Jiménez-Valverde A (2012) Insights into the area under the receiver operating characteristic curve (AUC) as a discrimination measure in species distribution modelling. Global Ecology and Biogeography 21(4), 498-507.
| Crossref | Google Scholar |
Johnson MC, Peterson DL, Raymond CL (2007) Managing forest structure and fire hazard—A tool for planners. Journal of Forestry 105(2), 77-83.
| Crossref | Google Scholar |
Kalantar B, Ueda N, Idrees MO, Janizadeh S, Ahmadi K, Shabani F (2020) Forest fire susceptibility prediction based on machine learning models with resampling algorithms on remote sensing data. Remote Sensing 12(22), 3682.
| Crossref | Google Scholar |
Kalies EL, Kent LLY (2016) Tamm Review: are fuel treatments effective at achieving ecological and social objectives? A systematic review. Forest Ecology and Management 375, 84-95.
| Crossref | Google Scholar |
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 [Preprint].
| Google Scholar |
Liang H, Zhang M, Wang H (2019) A neural network model for wildfire scale prediction using meteorological factors. IEEE Access 7, 176746-176755.
| Crossref | Google Scholar |
Liu Z, Wimberly MC, Lamsal A, Sohl TL, Hawbaker TJ (2015) Climate change and wildfire risk in an expanding wildland–urban interface: a case study from the Colorado Front Range Corridor. Landscape Ecology 30(10), 1943-1957.
| Crossref | Google Scholar |
Mansfield ER, Helms BP (1982) Detecting multicollinearity. The American Statistician 36(3a), 158-160.
| Crossref | Google Scholar |
Matsypura D, Prokopyev OA, Zahar A (2018) Wildfire fuel management: network-based models and optimization of prescribed burning. European Journal of Operational Research 264(2), 774-796.
| Crossref | Google Scholar |
Minas J, Hearne J, Martell D (2015) An integrated optimization model for fuel management and fire suppression preparedness planning. Annals of Operations Research 232, 201-215.
| Google Scholar |
National Interagency Fire Center (NIFC) (2020) ‘Spatial fireline records, 2020.’ (National Interagency Fire Center: Boise, ID, USA) Available at http://www.nifc.gov
Nino-Adan I, Portillo E, Landa-Torres I, Manjarres D (2021) Normalization influence on ANN-based models performance: a new proposal for Features’ contribution analysis. IEEE Access 9, 125462-125477.
| Crossref | Google Scholar |
O’Malley T, Bursztein E, Long J, Chollet F, Jin H, Invernizzi L, et al. (2019) Keras Tuner. Available at https://github.com/keras-team/keras-tuner
Patro S, Sahu KK (2015) Normalization: a preprocessing stage. arXiv preprint arXiv:1503.06462 [Preprint].
| Google Scholar |
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, et al. (2011) Scikit-learn: machine learning in Python. Journal of Machine Learning Research 12, 2825-2830.
| Google Scholar |
Pham BT, Jaafari A, Avand M, Al-Ansari N, Dinh Du T, Yen HPH, Phong TV, Nguyen DH, Le HV, Mafi-Gholami D, et al. (2020) Performance evaluation of machine learning methods for forest fire modeling and prediction. Symmetry 12(6), 1022.
| Crossref | Google Scholar |
Rachmawati R, Ozlen M, Reinke KJ, Hearne JW (2016) An optimisation approach for fuel treatment planning to break the connectivity of high-risk regions. Forest Ecology and Management 368, 94-104.
| Crossref | Google Scholar |
Reinhardt ED, Keane RE, Calkin DE, Cohen JD (2008) Objectives and considerations for wildland fuel treatment in forested ecosystems of the interior western United States. Forest Ecology and Management 256(12), 1997-2006.
| Crossref | Google Scholar |
Rodrigues M, De la Riva J (2014) An insight into machine-learning algorithms to model human-caused wildfire occurrence. Environmental Modelling & Software 57, 192-201.
| Google Scholar |
Rollins MG (2009) LANDFIRE: a nationally consistent vegetation, wildland fire, and fuel assessment. International Journal of Wildland Fire 18(3), 235-249.
| Crossref | Google Scholar |
Rosenblatt F (1958) The perceptron: a probabilistic model for information storage and organization in the brain. Psychological Review 65(6), 386-408.
| Crossref | Google Scholar | PubMed |
Sakr GE, Elhajj IH, Mitri G (2011) Efficient forest fire occurrence prediction for developing countries using two weather parameters. Engineering Applications of Artificial Intelligence 24(5), 888-894.
| Crossref | Google Scholar |
Scott JH, Gilbertson-Day JW, Moran C, Dillon GK, Short KC, Vogler KC (2020) Wildfire risk to communities: spatial datasets of landscape-wide wildfire risk components for the United States. (Forest Service Research Data Archive: Fort Collins, CO) Updated 25 November 2020. 10.2737/RDS-2020-0016
Seabold S, Perktold J (2010) Statsmodels: econometric and statistical modeling with Python. In ‘9th Python in Science Conference’. Austin, 28 June–3 July, 2010, pp. 57-61. 10.25080/Majora-92bf1922-011
Theobald DM, Romme WH (2007) Expansion of the US wildland–urban interface. Landscape and Urban Planning 83(4), 340-354.
| Crossref | Google Scholar |
Thomas D, Butry D, Gilbert S, Webb D, Fung J, et al. (2017) The costs and losses of wildfires. NIST Special Publication 1215(11), 1-72.
| Google Scholar |
Thompson MP, Calkin DE (2011) Uncertainty and risk in wildland fire management: a review. Journal of Environmental Management 92(8), 1895-1909.
| Crossref | Google Scholar | PubMed |
US Congress (2021) Infrastructure Investment and Jobs Act. Available at https://www.govinfo.gov/app/details/PLAW-117publ58
US Department of Agriculture (2022) ‘Wildfire crisis strategy: confronting the wildfire crisis.’ (US Department of Agriculture, Forest Service: Washington, DC) Available at https://www.fs.usda.gov/sites/default/files/fs_media/fs_document/Confronting-the-Wildfire-Crisis.pdf [accessed 1 April 2024]
US Department of Agriculture (2023) ‘Black Diamond Landscape Resiliency and Risk Reduction Project.’ (US Forest Service) Available at https://www.fs.usda.gov/project/?project=62591
USDA–USDI (2000) A report to the President in response to the wildfires of 2000. Available at www.fireplan.gov\president.cfm
Vasilakos C, Kalabokidis K, Hatzopoulos J, Kallos G, Matsinos Y (2007) Integrating new methods and tools in fire danger rating. International Journal of Wildland Fire 16(3), 306-316.
| Crossref | Google Scholar |
Wei Y, Rideout D, Kirsch A (2008) An optimization model for locating fuel treatments across a landscape to reduce expected fire losses. Canadian Journal of Forest Research 38(4), 868-877.
| Crossref | Google Scholar |
Weir JR, Kreuter UP, Wonkka CL, Twidwell D, Stroman DA, Russell M, Taylor CA (2019) Liability and prescribed fire: perception and reality. Rangeland Ecology & Management 72(3), 533-538.
| Google Scholar |
Woods K, Bowyer KW (1997) Generating ROC curves for artificial neural networks. IEEE Transactions on Medical Imaging 16(3), 329-337.
| Crossref | Google Scholar | PubMed |