

FireFormer: an efficient Transformer to identify forest fire from surveillance cameras
Yuming Qiao A B # , Wenyu Jiang A B # , Fei Wang A B * , Guofeng Su A , Xin Li C and Juncai Jiang A B
A B * , Guofeng Su A , Xin Li C and Juncai Jiang A B
A Department of Engineering Physics, Tsinghua University, Beijing, 100084, China.
B Institute of Safety Science and Technology, Tsinghua Shenzhen International Graduate School, Shenzhen, 518000, China.
C Foshan Urban Safety Research Center, Foshan, 528000, China.
International Journal of Wildland Fire 32(9) 1364-1380 https://doi.org/10.1071/WF22220
Submitted: 26 November 2022 Accepted: 18 July 2023 Published: 14 August 2023
© 2023 The Author(s) (or their employer(s)). Published by CSIRO Publishing on behalf of IAWF. This is an open access article distributed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (CC BY-NC-ND)
Abstract
Background: An effective identification model is crucial to realise the real-time monitoring and early warning of forest fires from surveillance cameras. However, existing models are prone to generate numerous false alarms under the interference of artificial smoke such as industrial smoke and villager cooking smoke, therefore a superior identification model is urgently needed.
Aims: In this study, we tested the Transformer-based model FireFormer to predict the risk probability of forest fire from the surveillance images.
Methods: FireFormer uses a shifted window self-attention module to extract similarities of divided patches in the image. The similarity in characteristics indicated the probability of forest fires. The GradCAM algorithm was then applied to analyse the interest area of FireFormer model and visualise the contribution of different image patches by calculating gradient reversely. To verify our model, the monitoring data from the high-point camera in Nandan Mountain, Foshan City, was collected and further constructed as a forest fire alarm dataset.
Key results: Our results showed that FireFormer achieved a competitive performance (OA: 82.21%, Recall: 86.635% and F1-score: 74.68%).
Conclusions: FireFormer proves to be superior to traditional methods.
Implications: FireFormer provides an efficient way to reduce false alarms and avoid heavy manual re-checking work.
Keywords: deep learning, forest fire identification, GradCAM, Interpretability analysis, self-attention mechanism, smoke detection, Transformer, wildland–urban interface.
Introduction
Forest fires are one of the most serious natural disasters in the world and have a profound impact on global climate change and carbon cycle (Larkin et al. 2014). In addition, forest fires also endanger social economy and even human safety. During the 37 years from 1977 to 2013, 208 fatalities due to forest fires were recorded across Greece, among which were 144 civilians, 47 fire professionals and 17 unidentified individuals (Diakakis et al. 2016). By the end of July 2021, there were 1251 wildfires in British Columbia, with an area of 4500 km2 (Ye Bai et al. 2022). On 9 March 2021, a forest fire in central and southern Argentina exceeded 20 km2, killing at least one person, injuring seven others, with 15 people missing (Ye Bai et al. 2022). In August 2022, extreme heat and drought in Chongqing, China caused nearly 10 forest fires, posing a serious threat to social security (Zuo 2022). When a forest fire is not detected and dealt with in time, it spreads rapidly and becomes difficult to control, resulting in serious disaster losses. As one of the most critical components for forest fire prevention and control, real-time monitoring method is able to provide the crucial early warning of the forest fires and reserve a valuable golden window period for fire control and rescue (Podur and Wotton 2010; Johnston et al. 2018).
When a forest fire occurs, smoke is often detected earlier than an open flame. Therefore, the current mainstream algorithms mainly identify the forest fire by monitoring smoke (Fernández-Berni et al. 2012; Wang et al. 2019). Conventional methods use smoke detectors to monitor the smoke from fuel combustion (Gutmacher et al. 2012). However, in the outdoor environment, smoke is more likely to scatter and difficult to detect. Fine particles such as air dust might cause interference to the detector, resulting in a limited monitoring range and low accuracy. Compared with smoke detectors, the image-based smoke recognition method has the advantages of wide monitoring range and low cost, and is widely used in the field of forest fire monitoring (Song et al. 2014). This image-based method designs an image processing algorithm to detect smoke motion blocks from video stream data. It introduces the unique timing information of video data, which combines the smoke block information of the previous frame and current frame to improve the robustness of the algorithm, enabling to achieve a near real-time smoke detection algorithm (Ko et al. 2013). Nevertheless, the forest landscape is large scale, thus the proportion of smoke in the monitoring image is relatively small. Traditional smoke detection methods perform poorly in such scenario. Unlike previous methods that rely on colour patch motion for detection, Tomkins, Benzeroual et al. (2014) proposes a night vision goggles-based method to achieve large scale forest fire detection. Zhou et al. (2016) proposed the maximum stable extreme value (MSER) method to extract local extreme regions of smoke, avoiding over-reliance on colour patches and motion block. This design makes it perform well in long-distance smoke detection tasks. However, these image-based smoke detection algorithms might be interfered by the geographical environment and meteorological conditions. Thus, more complex manual features are required to accurately extract the smoke in the complex forest landscape. For example, Ding et al. (2021) designed the spectral probability density to extract candidate smoke regions by comparing the colour histogram models in HSI (hue, saturation, and intensity) colour space. However, designing suitable and universal manual features is time-consuming and complicated, and their improvement in recognition performance is limited.
With the development of deep learning and the appearance of convolutional neural networks (CNNs), the performance in the field of computer vision, especially image recognition, has far surpassed traditional image processing methods. The proposed VGGNet (Very Deep Convolutional Networks) demonstrates the powerful feature extraction capability of CNNs, notably reducing the effort of complex manual feature design (Simonyan and Zisserman 2014). Subsequently, ResNet (Residual network) proposed the method of residual learning to solve the problem of poor optimisation effect of vanishing gradient in deep networks (He et al. 2016). Since then, more and more excellent networks have emerged, such as SENet (Hu et al. 2019), EfficientNet (Tan and Le 2019) and NFNets (Brock et al. 2021), proving the great advantage of deep learning methods for image recognition. In the field of smoke detection, deep learning-based applications are also gradually appearing. For example, Azim et al. (2022) collects roadside images to train a fuel types classification model, it can help to make better forest fire emergency responses according to the fuel type. Xu et al. (2019) proposed a combination of pixel-level and object-level convolutional neural networks to extract smoke saliency feature maps for smoke presence prediction, validating the usability of deep learning algorithms in the field of early monitoring of the forest fire. Khan et al. (2021) proposed DeepSmoke, a convolutional neural network for smoke recognition. When monitoring images are fed to the DeepSmoke network, the model can output the shape of smoke in the image, enabling end-to-end smoke location prediction and shape detection. Yuan et al. (2020) proposed a wave-shaped deep neural network, not only segmenting the smoke area but also predicting the density of it. Qiang et al. (2021) used two-stream framework composed of visual geometry group network to extract static features from single-frame image, while dynamic features are extracted by TRPCA (Time Domain Robust Principal Component Analysis), then fusing these two features to improve robustness and accuracy of the model in complex background smoke detection. Guede-Fernández et al. (2021) proposed a YOLO-PCA algorithm, which introduces the one extra detection scale strategy and integrates principal component analysis into the YOLOv3 model. During the training process, this model discards useless features based on the PCA feature selection results, which improves the speed and accuracy of smoke detection (Masoom et al. 2022).
Despite this, these deep learning-based algorithms are still inadequate in practical scenarios, especially in complex wildland–urban interface (WUI) (Ahmed et al. 2018; Villacrés et al. 2019; Jiang et al. 2021), the fire behaviour is more complex in local details (Mell et al. 2010; Jiang et al. 2022a). Due to the presence of many smoke disturbing factors in complex landscapes, such as water mist in the air, smoke emitted from industrial premises, smoke from burning incense in temples, and smoke generated by cooking, etc. These interfering smokes have significantly similar characteristics with the smoke generated by forest fires in surveillance video data, which makes it difficult for existing algorithms to effectively distinguish different smokes and thus generate excessive false alarms. Some improved methods have been proposed to distinguish fire smoke from other smokes. He et al. (2021a) designed an efficient attention model based on deep fusion CNN to distinguish fire smoke from fog in severe weather. Luo et al. (2015) took a compressed video approach to extract the unique motion trajectory features of fire smoke to distinguish different smoke. Ryu and Kwak (2022) considered the effect of complex flames on smoke detection and pre-processed the images via HSV (hue, saturation, value) colour conversion and corner detection, then dark channel approach was adopted to pre-process the smoke regions. The final trained CNN model achieved a high level of performance in flame and smoke recognition. Although these methods are able to distinguish fire smoke from meteorological smoke, it is still difficult to distinguish fire smoke from other types of smoke, such as industrial smoke and cooking smoke. These smoke and fire smoke have very similar colour and motion characteristics, which are the main reasons for the large amount of false alarms in existing forest fire identification algorithms (Manzello et al. 2018).
Extracting unique features of forest fire smoke from video images that are different from other smokes is the key to reduce false alarms. Existing CNN-based smoke recognition models mainly focus on detecting the presence or absence of smoke in images, with little research on distinguishing between smoke types. The core of these models is to learn the optimal feature extraction operator and then adopt the trained operator to perform convolutional operations on the image and extract the deep image features. These features extracted by the convolution kernel operator are mainly visual structure and low-level features (Hu et al. 2018; Amit et al. 2020; Stanford University 2020) such as the basic units that constitute the visual elements (key points, boundaries of objects). These CNN-based models extract image features at different scales by cascading convolutional layers and fuse them to enrich feature information. However, receptive fields of the network will become larger when the network structure gets deeper. Nevertheless, the feature information of small targets is easily ignored due to the pooling operations in the cascade structure. This has a great impact on image feature extraction in large scale wildland with high-point surveillance cameras. In contrast, the novel Transformer model (Vaswani et al. 2017), built entirely based on the self-attentive mechanism (He et al. 2021b), also has a stunning performance in the field of computer vision. By analogy with the natural language processing task, the vision Transformer pioneers the segmentation of images into different patches and then embeds each patch into a high-dimensional vector through a linear layer. This design is able to extract image contextual features by computing the similarity between different patch vectors (Dosovitskiy et al. 2021). Transformer focuses more on the connection between visual elements of images. It learns the association pattern between patches built into one object and the constructed relationship between different object blocks in an image. For example, I2R-Net adopted Transformer to build intra- and inter-human relation model. This model extracted association information between human and human image block objects to achieve accurate recognition of occluded joints (Ding et al. 2022). For the fire smoke identification in the complex WUI landscape, the relationship between smoke and other environmental targets is equally important to distinguish different types of smoke than the feature information such as smoke shape and location. Therefore, the Transformer model has good potential for distinguishing different types of smoke and reduce the false alarms by analysing the feature relationship between smoke image blocks and natural element image blocks.
In this paper, a Transform-based identification model named FireFormer is proposed to evaluate the forest fire risk probability from surveillance video images of wildland–urban interface (WUI) landscape. This model provides a novel approach to better distinguish the smoke from different sources. It adopts Transformer’s self-attention mechanism to compute the correlation of image patches, enabling the model to be more focused on extracting high-level features of fire smoke-related regions. To address the high complexity of patch division in Transformer computation, our FireFormer adopts a shifted window-based self-attention method to reduce the patch size while maintaining the amount of image feature information. In addition, to rise the interpretability of the FireFormer, we introduce the GradCAM algorithm to analyse interest area of our model and elaborate the association features between the smoke region and surrounding environmental elements in the complex WUI landscape.
Materials and methods
Problem definition
The high similarity between forest fire smoke and other smokes in the wildland–urban interface (WUI) landscape becomes the main reason that existing smoke detection algorithms perform poorly in forest fire identification. The smoke is mainly the products of combustion. However, industrial fumes and cooking smoke have almost no risk of causing forest fires, but smoke detection systems still identify them as fire alarms, leading to consuming a lot of time for manual rechecking. To analyse the impact of different types of smoke on the forest fire monitoring system, a WUI in Nandan Mountain, Foshan City, Guangdong Province in China was selected as the study area. The alarm data was then collected from the surveillance camera set up in Nandan Mountain. We then divided these alarm data into two categories: (1) high-risk alarms, which are the smoke alarm generated by real forest fire or wildland burning, and requires continuous monitoring and rapid response; and (2) low-risk alarms, which are the false alarm data including water mist, industrial smoke, temple smoke, and cooking smoke; a large number of which is time consuming for operators to review.
In order to solve the problem of high false alarm rate of traditional methods, the association between the smoke and natural elements in the WUI landscape can be considered to make a difference. There are significant differences between the natural environment of smoke from forest fires and other types of smoke. For example, industrial smoke is mostly found in thermal power plants, where the environment surrounding the smoke always consists of exhaust fume pipes, plants, and other industrial buildings. Cooking smoke is mainly surrounded by residential houses, wells, cultivated fields and other living areas; while high-risk alarms such as wildland burning smoke and forest fire smoke are mostly surrounded by forest trees. The use of different features of natural elements to identify different types of smoke is an important approach to decrease the high rate of false alarm in traditional smoke detection algorithms.
The Transformer model has the ability to extract the correlation features between different patches of the image, enabling to calculate the similarity intensity between the smoke blocks and the surrounding environmental blocks (Dosovitskiy et al. 2021). This intensity indicates the type of smoke. Therefore, this paper proposed the novel Transformer-based model FireFormer for the existing forest fire monitoring systems. When a smoke is detected by the monitoring system, it would be then sent and processed by the FireFormer model. For alarm signals identified as low-risk false alarms, the captured surveillance images are continuously monitored for a period of time until the alarm is eliminated. For high-risk alarms, the alarm data is transmitted to the staff immediately for manual review and rapid response. In addition, to better interpret the model results, the GradCAM algorithm is adopted to analyse the attention region of the FireFormer model. The flow chart of forest fire alarm diagnosing is in Fig. 1.
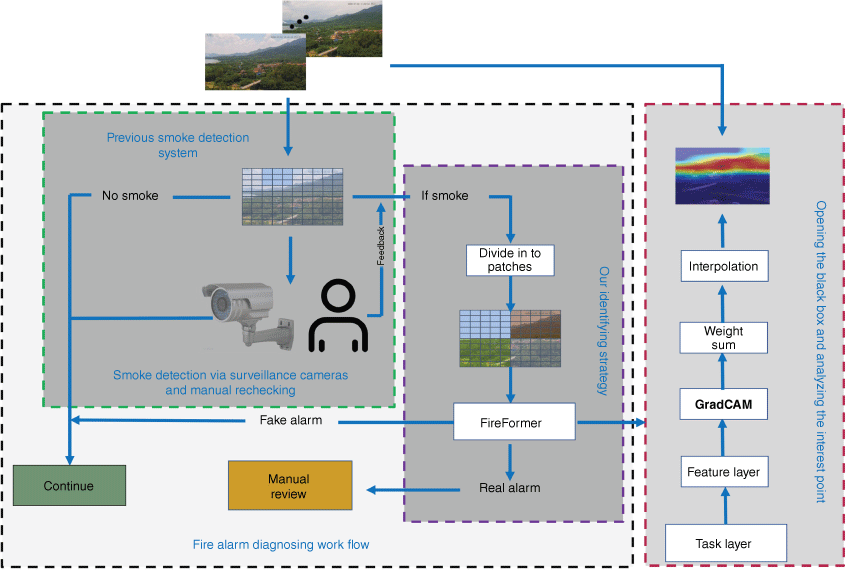
Data preparation
Nandan Mountain is located in Nanshan Town (Luankou Overseas Chinese Economic Zone), Sanshui District, Foshan City, Guangdong Province in China, with an area of 60 km2 and a mountain elevation above 500 metres. The whole valley is covered with dense primary forest, with nearly 3000 plant species initially found, and adjacent to residential and industrial areas, a typical WUI landscape with a high risk of forest fire. A forest fire monitoring PTZ (Pan/Tilt/Zoom) camera was set up at the summit of Nandan Mountain, the high point camera is rotated by DC (Direct Current) brushless motor with visible focal length lens range better than 8–560 mm: 70×. The total lens pixels are higher than eight megapixels and the maximum resolution is 3840 × 2160. Here, we collected all alarm data from Nandan Mountain High Point Camera from 10 January 2022 to 9 August 2022, and labelled the alarm types with strict manual review. We then intercepted continuous camera video frames at the moment of the alarm and eliminated the low-quality image frames caused by camera rotation and zooming. Finally, a total of 1664 images were collected from the historical alarm data. these smoke alarms were distinguished with high risk for the occurrence of forest fires (e.g. forest fires, wildland burns) and low risk (meteorological smoke, industrial smoke, cooking smoke) (Table 1).
| Class | Total | Type | Image | Properties | Label |
|---|---|---|---|---|---|
| Forest fire | 2 | High risk |  | Dangerous | 0 |
| Wildland burning | 879 | ||||
| Industrial smoke | 338 | Low risk |  | Safe | 1 |
| Cooking Smoke | 367 | ||||
| Temple burning incense | 69 | ||||
| Else(mist) | 9 |
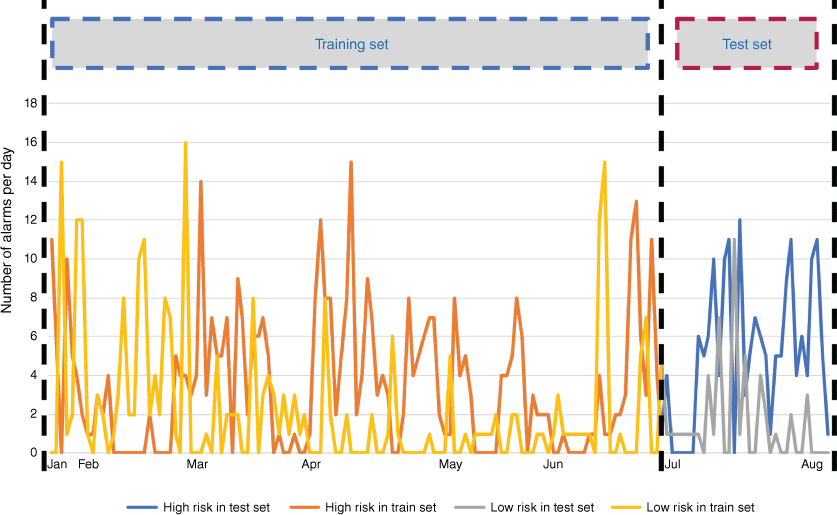
Considering the influence of time span and season on alarm images, the alarm data of the first two quarters (January 2022–June 2022) is used as the training samples (1411 images, high risk: 669, low risk: 742), while the alarm data from 2 months (July 2022–August 2022) is used as the testing samples (253 images, high risk: 212, low risk: 41) of the model. The data division strategy is in Fig. 2. There are a total of 1664 images (high risk, 881; low risk, 783) in our dataset.
FireFormer framework
Self-attention is a novel neural network architecture that extracts high-order features of an image by analysing the potential interrelationships between different patches of the image (Dosovitskiy et al. 2021). The proposed FireFormer is a Transformer-based identification model that extracts the correlation features between the smoke area and the surrounding environmental region, and then achieves the accurate identification of forest fire risk probability. The traditional Transformer also has some limitations. For example, the long input sequence will bring a huge computational burden. Therefore, the maximum length of the input sequence accepted by the Transformer is generally 512. However, the number of patches generated by blocking a high-resolution image (i.e. the max size of surveillance video frame is 3840 × 2160.) can be much larger than 512. Therefore, the Transformer usually reduces the number of patches by decreasing the image resolution or increasing the size of patches. However, both strategies mentioned above will reduce the amount of information in the input data, thus limiting the performance of the model. Thus, we proposed a self-attention mechanism to achieve the extraction of contextual semantic information by sliding windows without increasing the patch size (Liu et al. 2021b). The framework of the FireFormer is in Fig. 3.
Framework of FireFormer. (a) Overall architecture of FireFormer. MLP, Multilayer Perceptron; LN, Layer Norm; WSA, Window self-attention; SWSA, Shifted window self-attention. (b) Shifted window strategy. (c) An example of generating self-attention vector.
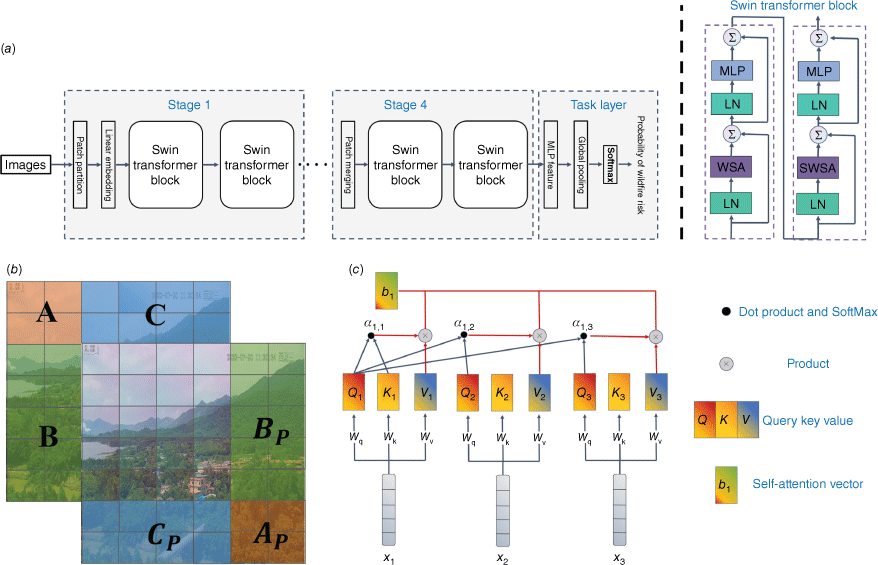
The overall architecture of the model is in Fig. 3a. The first step is patch partition. The input image with the size H × W × C is divided into four windows, while each window. Second, the images in each window are further divided into several patches with the fixed patch size M × M. These patches are then flattened in to vectors x, while x . Third, these patch vectors are processed into higher-order vectors by the Linear embedding layer, and its calculation process is in Eqn 1:
where WLE is the weight of lnear embedding layer, x is the patch vector, is the transformed tensor, WSA is window self-attention, and SWSA is shifted window self-attention in swin (shifted windows) Transformer block, and LN is Layer Norm introduced to normalise u before it is fed into calculating module such as WSA and SWSA, so that the input vectors will obey normal distribution and thus enhance the robustness of the model (Ba et al. 2016). Tensor u is then fed directly into the WSA of swin Transformer block (Liu et al. 2021b). However, this approach only supports the calculation of self-attention within each window, which only considers local features and lacks contextual semantic information of the global image. Therefore, a SWSA is implemented to extract this contextual information. The SWSA pans the original window two patches to the lower right and generates a new window. This new window has both the part in the original window and the new region from other windows. As shown in Fig. 3b, after the panning operation, the image region A, B, C change to AP, BP and CP in the new window. Then the self-attention calculation of the SWSA is able to extract the approximate global image information. The computation process of core self-attention is in Fig. 3c, where the variables Q (query), K (key), V (value) are defined in Eqn 2:
where u is the result of Linear embedding within each window, WQ ∈ R(N,N) is the linear mapping operation constructed by vector multiplication, N is the dimension of each patch vector in u. Q ∈R(d,N) represents the attributes matching with the current patch in Transformer, where d is the number of patches in each window. Similarly, Wk ∈R(d,N) and WV ∈ R(d,N) are also the linear matrix to generate the patch attributes K and V, respectively. Then the dot product function is adopted to analyse similarity between patches as shown in Eqn 3:
where dk ∈ R(d,d) is the parameter to prevent the dot product of Q and KT from being too large. Its value is N, means the dimensionality of Q, K. Then these similarity parameters are normalised by the Softmax operation (Elfadel and Wyatt 1993), as defined in Eqn 4:
The attention vector can be calculated by summing up the multiplication of Vi and normalised weight ai, the process is shown in Eqn 5:
where w ∈ R(d,N) represents the attention vector (which is calculated by accumulating the attention components of all patches), and n is the number of components. There is a residual block to connect input patch vector u and attention vector w to form a residual learning strategy y = u + w. After this residual block, a non-linear activation function is applied. Unlike the neural network architecture that each layer is followed by an activation function, activation functions are not used in self-attention module like WSA and SWSA. This is due to the fact that the calculation of attention vector mainly depends on linear process in Eqns 2–5, while nonlinear activation function may disturb the distribution of features Q, K and V (Welling and Kipf 2016). However, non-linear activation function is essential for improving the model’s ability to fit complex function mapping. Therefore, we adopt the GeLU activation function (Hendrycks and Gimpel 2016) after the residual block, as defined in Eqn 6:
where y is the residual connection result, P is the probability calculated by the cumulative distribution function, and μ and σ is mean and variance of the activation layer, respectively. Compared with ReLU activation function (Glorot et al. 2011) wildly used in CNNs, GeLU is derivable at zero point and add random regularisation to improve generalisation capability of the model.
In addition, compared with CNNs models that expand the image receptive fields by adjusting the kernel size, stride size, or pooling size to fuse image features at different scales (He et al. 2016; Huang et al. 2017), the Transformer-based models adopt a patch merging method to down-sample the feature map to improve the receptive fields. After the stage block, the patch merging layer is used to down-samples to half and four times of the size and channel of the input feature respectively. As shown in Fig. 4, the patch merging method selects patches in the row and column directions at intervals of two respectively. The selected patches are then concatenated together as a new tensor. At this time, the channel dimension becomes four times of the input (because H, W are reduced by two times each). A fully connected layer is then used to adjust the channel dimension to twice of the input, so that the scale of the feature map and the number of channels can be changed to achieve feature extraction with a variable scale. After four stages, the model is able to encode high-order features of the image. These features will be the input of the multilayer perceptron (MLP) for feature mapping operation. Then the global pooling algorithm is applied to calculate the mean value of the feature vectors of all patches. Finally, the fully connected layer (output layer) is used to perform the classification by one-hot encoding and Softmax activation function. This classification result indicates the probability of a forest fire in the image landscape.

GradCAM
The GradCAM module can calculate gradient reversely from output layer to feature layer and thus generate a gradient map to analyse the interest area of the FireFormer model and visualise the contribution of different image patches in forest fire identification (Selvaraju et al. 2020). The calculation process of GradCAM is in Fig. 5.
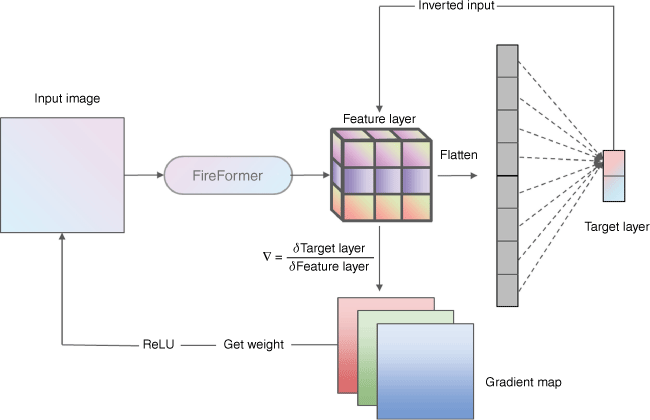
After the input image is processed by FireFormer, the feature output by the last swin Transformer block is adopted as X tensor for GradCAM module, as defined in Eqn 7 below:
where P is the final output probability value of the model without Softmax activation function, W is the weight of the fully connected layer, fc refers to the mapping operation of the linear layer, and flatten(·) is flatten operation. The gradient calculation of P to the feature layer X is defined as Eqn 8:
where W0,…Wi are the fully connected layer weights, and ReLU activation function (Glorot et al. 2011) is adopted to rectify the negative values, since negative values often represent a strong correlation with another category. The fully connected layer weights W0,…Wi are then reshaped to fix size of R∈[Xc, Xw, XH], which are the number of channels Xc, width Xw, and height XH of the feature map respectively. The ReLU is shown in Eqn 9:
The weights of each channel are then calculated based on the gradient ∇P, as defined in Eqn 10:
where the mean value of the gradient in each channel is calculated as the weight of this channel, and h and w are the height and width of the feature map, respectively. The weight W and gradient ∇P within each channel are then multiplied and summed up as the heat map of interest area. The process is in Eqn 11, where c is the number of channels of feature map:
Training configuration
To train our network, we use the training set data that has been partitioned from the original data and use the rest of the data as the test set. The data splitting strategy is mentioned in the section ‘Data preparation’. The Transformer-based BERT model (Devlin et al. 2018) has demonstrated the surprising advantage of the pre-train method. This method makes the model to train on a relevant large dataset first, and then the model is fine tuned to better fit target tasks. The ImageNet dataset is one of the most massive datasets in image recognition and widely adopted as the pre-trained dataset (Krizhevsky et al. 2012). Therefore, our FireFormer model also adopts the swin Transformer-large weights pre-trained on ImageNet as initialisation parameters. The model code is implemented based on the Pytorch framework, and all experiments are conducted on an Nvidia P5000 (16g) GPU with 32 GB of RAM. The total number of iterations is 100 epochs, batch size is 32 samples, and the initial learning rate is 0.00025. The network uses cosine decay strategy to adjust learning rate and applies a linear warm-up strategy to initialise the learning rate from 0 to 0.00025 in the first three epochs. AdamW is then used to optimise the network. AdamW is an adaptive optimiser with weight decay, it has a great advantage in increasing the robustness of the model and preventing the network from over-fitting (Loshchilov and Hutter 2017). Weight decay value is set to 0.05; that is, adding the L2 norm regularisation term of the weight matrix (Cortes et al. 2009) to the loss function, and using 0.05 as the coefficient of the regularisation term. This will produce the effect of making the weight w smaller during the model training, reducing the model complexity, fitting the data better, and avoiding the phenomenon of excessive fitting weights in over-fitting. Meanwhile, an early-stopping approach was adopted to prevent the model from over-fitting (Wu and Liu 2009). If the model does not maintain an accuracy improvement during the last 60 epochs, we consider that the model has reached convergence status. Finally cross-entropy loss function is adopted to quantify the error between prediction of network and ground truth.
For the RGB images in training dataset, they are cropped to a uniform size of 224 × 224 with centre cropping method (Research F.A. 2017) and transformed to tensor for the input of FireFormer. Compared with the traditional method of resizing the tensor to a fixed size, centre cropping does not change the resolution of the image, and the original image features can be better preserved. Finally, to address the problem of data balance and the measurement of single-category precision in the classification task, four commonly used evaluation metrics in classification task are adopted to comprehensively evaluate the performance of FireFormer, as defined in Eqns 12–15:
where TP is true positive with positive label and positive model prediction, TN is true negative with negative label and negative model prediction, FP is false positive with positive prediction but negative label, and FN is false negative with negative prediction but positive label.
Results
Model results
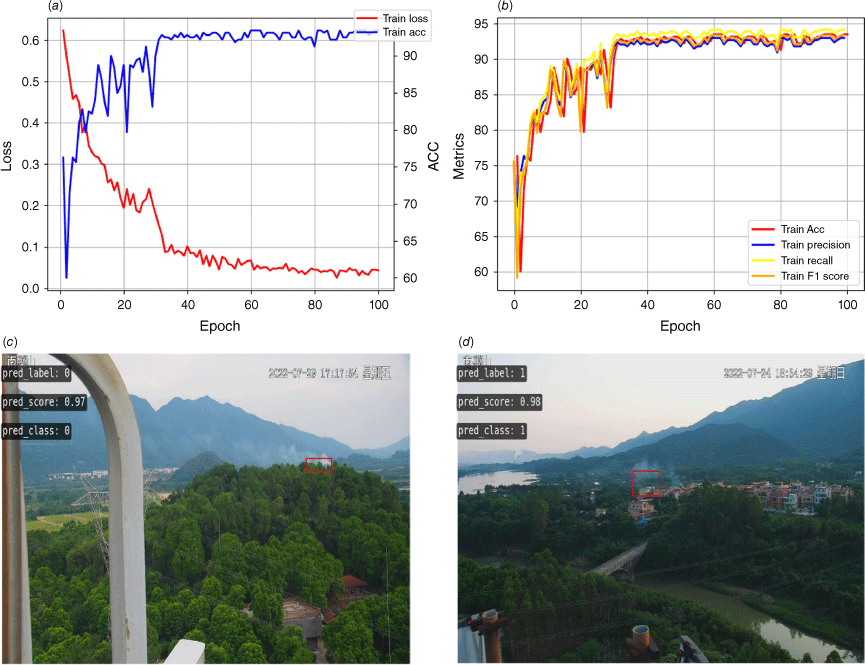
The training result of FireFormer yielded an overall accuracy of 93.44%, an average recall of 94.11%, an average precision of 92.94%, F1 score of 93.31%, and a converged loss value of 0.025 (Fig. 6a, b). On the testing dataset, the FireFormer model performs the highest average recall of 86.635%, overall accuracy of 82.21% and F1-score of 74.68%, respectively. Fig. 6c, d demonstrates the identification examples of FireFormer for high-risk alarm data and low-risk alarm data in the testing set, proving that our model has excellent capability of forest fire risk identification.
Training process. (a) Network training accuracy and loss curve, (b) training metrics curve, and (c) WUI smoke reclassification cases of high-risk alarm (wildland burning); (d) WUI smoke reclassification cases of low-risk alarm (cooking smoke).
It should be noted that to better evaluate the universality of the model, the data set should be constructed to minimise the distribution similarity between the training set and the test set (Ovadia et al. 2019). Therefore, in this paper, we adopted a data partition strategy that splits the data by different seasons (alarm data from January to June for training model; model testing from July to August), and demonstrated a competitive model performance (OA: 82.21%, Recall: 86.635% and F1-score: 74.68%). Compared with this, the mixed data splitting strategy (stratified random sampling) achieved better performance (ACC: 90.51%, Recall: 89.12%, F1-score: 85.63%). However, this strategy leads to a slightly weaker robustness and universality of the model, which means it may not preserve the same competitive performance in other differentiated scenarios. These differences (e.g. image changes caused by seasons, weather.) are relatively common in real large-scale WUI landscape, which demands a higher level of model robustness.
Understanding the results via visualisation
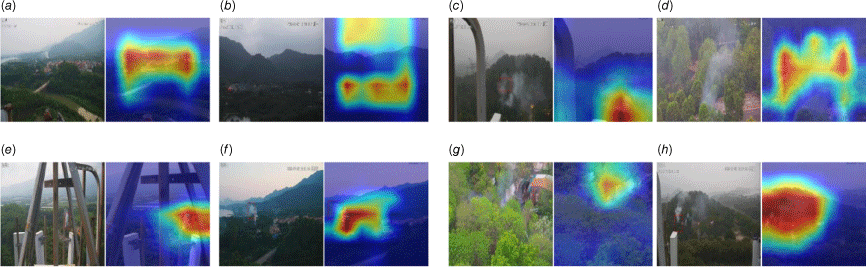
The output from the last stage of FireFormer is processed by the CardCAM module to generate the feature map and visualise model’s interest area. The size of the feature map is the result of the original image after down-sampling, so the generated gradient map also needs to be interpolation up-sampled to the size of the original image. As shown in Fig. 7, we compared the visualisation results of the gradient map with the original image and found that FireFormer’s attention area in the input image is mainly on the location of the smoke and the surrounding environmental region. FireFormer tends to extract features of attention areas to estimate whether this alarm is risky or not. For example, as shown in Fig. 7a, the model focuses on the forest and house elements around the smoke, and considers the spatial relationship between the smoke site, forest, and the house on the image to identify it as a risky wildland burning behaviour. In Fig. 7b, the network focuses on the smoke and the surrounding houses instead of forests, and identifies it as a low-risk cooking behaviour in villages. The same is true for Fig. 7c, where the network focuses all of its attention on the house building area in the lower half of the image, while consciously avoiding the forest area in the upper half of the image, which is unrelated to this smoke. In Fig. 7d, FireFormer focuses more on the forest elements in the image, which has something in common with the elements considered in the manual review of the alarm messages. Similarly, it can be seen more clearly in Fig. 7f, g that the attention of the model is mainly focused on the smoke and the part of the area around the smoke. It is also evident from Fig. 7e that this attention mechanism is not affected by partial occlusion. In the large-scale scenario like Fig. 7h where the residential area intersects with the forest area, FireFormer expands the area of interest to some extent with the smoke area as the centre, considering the role and spatial feature of the forest area and the residential part on the smoke area. These visualisation results also proved the reliability and validity of our FireFormer in forest fire identification.
Interest area visualisation via GradCAM module. (a) High-risk alarm example, (b) small scale low-risk cooking smoke recognition, (c) large scale low-risk cooking smoke recognition, (d) hard case of high-risk burning of wasteland around residential area, (e) recognition instance while smoke is obscured by signal tow, (f) example that attention of FireFormer focuses on smoke and its surroundings, (g) rxample that attention focuses on smoke and resident housing nearby, and (h) example that FireFormer expands interest area while the spatial feature of smoke is hard to extract.
Discussion
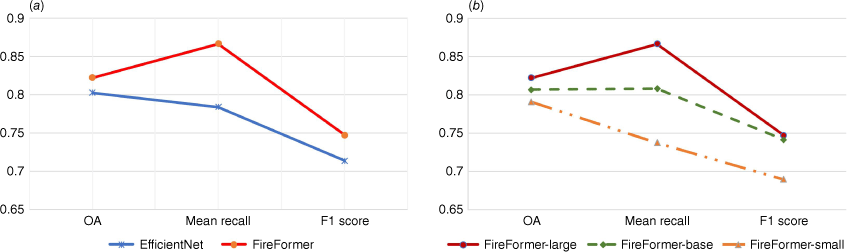
To compare the performance between Transformer-based FireFormer and convolutional neural networks (CNNs) in the field of forest fire identification, we used EfficientNet (Tan and Le 2019), which currently has excellent performance in image recognition, as a comparison CNN model. The backbone network of EfficientNet consists of mobilenetv3 (Howard et al. 2019) that is a sequence of MBConv module. This MBConv combines the advantages of residual block, inverted residuals, and depth-separable convolution techniques, enabling to reduce model parameters while keeping the depth of the model. In order to compare them more fairly, the EfficientNet weights are also initialised with the pre-trained weights trained on ImageNet, and the number of iterations and training strategy are the same as FireFormer. Finally, the highest overall accuracy of EfficientNet on the testing set is 80.24%, the average recall is 78.37%, and the F1-score is 71.33%. In comparison, our proposed FireFormer (OA: 82.21%, Recall: 86.635%, F1-score: 74.68%) has a significant advantage in model performance (Fig. 8a). In addition, the representation of attention vectors in Transformer mainly relies on the Q, K, and V matrices of each patch vector. And the multi-head self-attention mechanism can effectively improve the representation of Q, K, and V. Therefore, we also conducted ablation experiments for different numbers of attention heads, and constructed the FireFormer-small (the number of self-attention heads is 3, 6, 12, and 24 in each stage block), FireFormer-base (the number is 4, 8, 16, and 32) and FireFormer-large (the number is 6, 12, 24, and 48), respectively. As shown in Fig. 8b, the performance of above FireFormer models indicate that reducing the number of FireFormer self-attention heads will lead to a decrease in model performance.
Performance comparison. (a) Comparison of CNN and Transformer, and (b) comparison experiments of different numbers of self-attention heads in each stage in FireFormer.
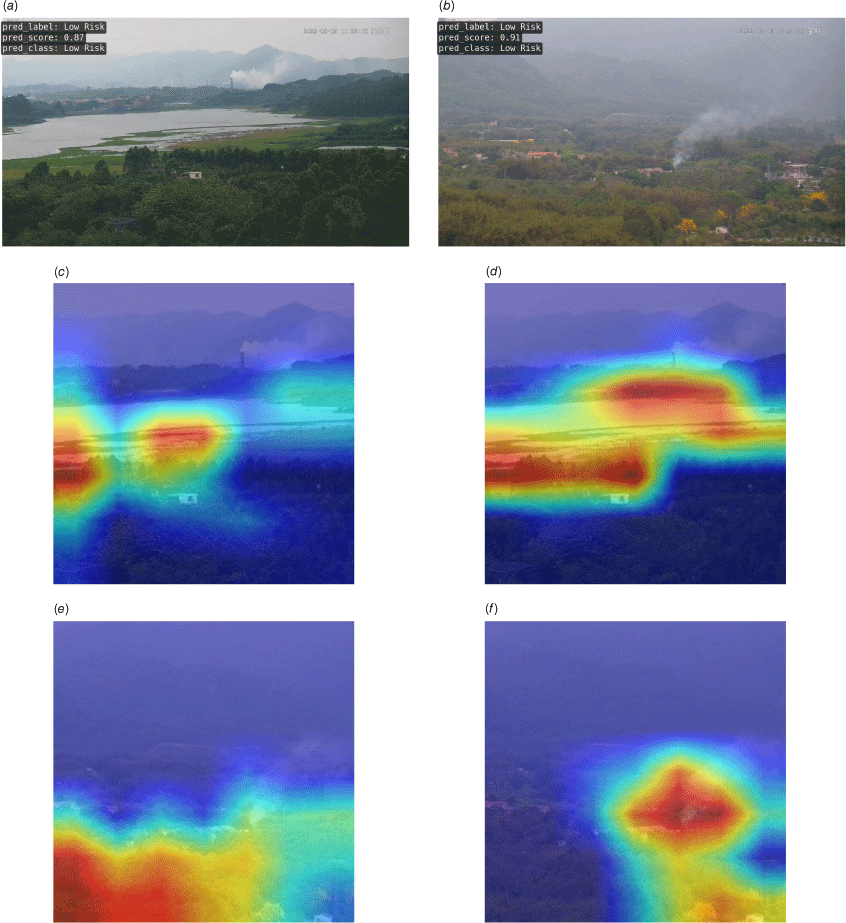
To further demonstrate the robustness of FireFormer in complex scenarios with multiple smoke sources, more challenging cases are collected for evaluation. As shown in Fig. 9. Fig. 9a, b are both challenging cases that FireFormer correctly identified the smoke while CNN failed. Fig. 9a is the identification result (P = 0.87) of FireFormer model in a multi-smoke source scenario of industry-forest region (IFR). Fig. 9b is the identification result (P = 0.91) of FireFormer in a resident-forest region (RFR) scenario. Fig. 9c, d are the attention analysis results of CNN and FireFormer, respectively, using GradCAM module in the IFR case in Fig. 9a. It can be seen that FireFormer focuses more on the area of smoke and surrounding environmental factors, while CNN completely ignores the important contribution of smoke block and surrounding environmental factors to smoke identification. Fig. 9e, f are the comparison results of attention areas of two models in the RFR case in Fig. 9b. Similarly, FireFormer’s attention is completely focused on the area of residential houses and surrounding forests, while CNN puts its attention on the forest area at the lower left corner of the image, which has nothing to do with the type of smoke risk. The experimental results show that our FireFormer model can maintain precise attention areas in challenging cases (i.e. industry-forest and resident-forest landscape) and accurately distinguish different types of smoke with prediction P-values of 0.87 and 0.91, respectively. However, as described in the Results section, the model has slightly weaker robustness in different scenarios. This limitation is mainly caused by the insufficiency of the current dataset (not covering the whole year). When more data (covering all seasons of the year) is collected, the model will be fully trained. The problem of performance gap in diverse scenarios caused by different seasons will be well solved. In this case, the model performance differences under the two data partition strategies will be narrowed.
Performance comparison in challenging cases with multiple smoke sources between FireFormer and CNN. (a) Multiple smoke sources in industry-forest region (IFR). (b) Multiple smoke sources of resident-forest region (RFR). (c) Interest area visualisation of CNN in IFR. (d) Interest area visualisation of FireFormer in IFR. (e) Interest area visualisation of CNN in RFR. (f) Interest area visualisation of FireFormer in RFR.
The performance of image recognition largely depends on the receptive field of the final extracted feature map on the original image size. If the receptive field is smaller than the target size, the performance of the model is easily degraded due to incomplete feature extraction, thus the study of the receptive field is very important for these deep learning-based models (Luo et al. 2016). Therefore, the receptive field of forest fire identification algorithm is analysed in three steps as follows. First, the mean value is calculated by channel dimension for the centroids of the feature layer. Second, the mean value is back-propagated back to the input layer. Third, step one or two is repeated using a sufficient number of sample data to reduce the receptive field bias caused by excessive variance in individual images. Back-propagating a point in the feature map to the input layer represents the mapping range of that point on the original image size. There are some similarities in the receptive field maps generated by the GradCAM module (Fig. 10).
Receptive fields of EfficientNet. (a) 2nd layer in backbone, (b) 3rd layer in backbone, and (c) 5th layer in backbone.

The results of the receptive field calculation for the output features of the second, third and fifth MBConv layers in EfficientNet are consistent with the statement of the mapping region of the CNN (Feifei 2020). The feature map of the second layer is the result of the two convolutional layers and pooling layer, and the receptive field is affected by the convolutional kernel size and the pooling size. Kernel size is 3 × 3, and pooling size is 2 × 2, so the receptive field is small compared to the image size of 224 × 224. As shown in Fig. 10b, the receptive field is still small due to the lack of convolutional layers and pooling operations at the third layer; while in Fig. 10c, the receptive field is expanding as the network depth increases. However, it can be seen that the receptive field have many discontinuous granular voids, which leads to a reduction of its actual receptive field. This may cause the model to ignore some of the features within the receptive field. The expansion of the receptive field in CNN models relies on the pooling layer as well as the dilated convolution layer. Both scale transformation methods ignore part of the features of the original image, resulting in the loss of feature information extraction. In contrast, the FireFormer proposes a patch merging method to overcome the shortage of network receptive field, enabling to retain feature information to a large extent. This may explain the result that Transformer-based model with the self-attentive mechanism performs better than the CNN-based model in the forest fire identification task.
Surveillance image data with poor model result was collected to analyse the limitations of the current FireFormer model. The images and activation maps of two mis-identified samples are shown (Fig. 11). In Fig. 11a, the model indeed takes the smoke area as the interest area. The natural environmental region around the smoke is also within the interest of the model. However, the surveillance camera is directly facing the sunlight in this image, which leads to poor image quality due to overexposure. Moreover, the smoke is between the forest area and the residential area, making it more difficult for the model to capture the core features and thus lead to its mis-identification. In Fig. 11b, the smoke is in the leftmost part of the image. However, the resize method during the image pre-processing would stretch the original image and cause features to be distorted. Meanwhile, in order to reduce the computational burden of the model, we adopt a centre crop strategy for image pre-processing to reduce the image size. This crop operation may result in the smoke region to be truncated. Thus, the model fails to find the smoke and identifies the image as low-risk alarm. The appearance of smoke at the image edge in the surveillance video data is a chance phenomenon, as the smoke block will be in a non-edge position in the subsequent frames during camera rotation.

Conclusions
Early monitoring of forest fires is of vital importance for timely warning, rapid response, and disaster loss reduction. However, in complex scenarios like WUI, traditional forest fire identification algorithms based on surveillance images are often disturbed by low-risk smoke such as industrial smoke, temple incense burning, and residential cooking smoke, which in turn push misidentified alarm signals to the monitoring agencies, resulting in the heavy manual re-checking work. To address the challenges faced by existing models, we propose a novel Transformer-based model FireFormer to accurately predict forest fire risk probability and reduce the impact of other smoke types. FireFormer uses a shifting window approach to improve the ability to extract image features without losing contextual information while maintaining the patches size. In addition, the patch merging method inspired by CNN models is applied to achieve feature map scale variation, which in turn improves the feature representation capability of the model. Furthermore, the GradCAM algorithm is adopted to explain the FireFormer model. This algorithm calculates gradient reversely from output layer to the feature layer and generate interest area of the model. Based on the interest area map, it can be analysed that the FireFormer has the ability to focus on extracting features of smoke and its surrounding environment region. Finally, a series of comparison experiments were conducted to verify the superiority of this FireFormer. In the testing dataset, FireFormer shows excellent performance (OA: 82.21%, Recall: 86.63%, F1: 74.68%), which can significantly reduce the false alarm rate of forest fires and avoid the heavy manual review work.
The Transformer-based model is inspiring for the field of forest fire identification. Nevertheless, there are still some limitations in this study. First, the identification algorithm in this paper only considers a single frame of surveillance video data, and further research is necessary to analyse the temporal information in the continuous video frames. For example, the DCpose algorithm combines the key point feature map information in the before and after frames of the video to improve the accuracy of pose estimation (Liu et al. 2021a). Second, meteorological data such as temperature and humidity are significantly correlated with the occurrence of forest fires. Therefore, using multi-sensor method to fuse meteorological data into current model is promising to improve the identification accuracy and robustness of the model (Milecki and Rybarczyk 2020; Khan et al. 2022). In addition, forest fire detection in night environment is also important, although there are no smoke alarms at night in our sample dataset. The image quality of conventional visible sensors in dim light is significantly degraded, leading to poor usability of smoke identification algorithms. Therefore, data fusion strategy with infrared spectral sensors is one of the effective approaches to address forest fire monitoring at night (Sousa et al. 2020; Dufour et al. 2021). Furthermore, it is also very worthwhile to build a space-air-ground linkage forest fire monitoring system (Jiang et al. 2022b) by considering the multi-source data fusion strategy of satellite remote sensing (Ba et al. 2019), unmanned aerial vehicle (Kalatzis et al. 2018) and high-point camera for improving the dynamic monitoring ability of forest fire. Third, the alarm dataset used for current FireFormer model is only from January to August. It misses the alarm from late autumn to winter. Due to the variability in different seasons, the identification accuracy of the model may be drop slightly. In the future, it’s necessary to further construct a more comprehensive dataset to improve model performance in each time period. Fourth, although current FireFormer model presents excellent performance on the dataset, it might be limited in its universality since this dataset was generated from the only one surveillance camera in Nandan Mountain, where the fuel type was mainly evergreen broad-leaf forest and evergreen shrub-grassland. The limited data constrains model ability to recognise more diverse smoke characteristics in different scenarios. Namely when other WUI landscapes are far different from the Nandan region, FireFormer model may fail to maintain its performance superiority. This is a common phenomenon in these data-driven models and can be addressed by collecting more forest fire alarm data from various WUI landscapes. In the future, it is necessary to collect more camera data from different scenarios to further improve the universality of the model. Fifth, smoke source localisation (Göltaş et al. 2017; Varghese et al. 2022) was not considered in the current model. When smoke is at different distances from the camera, there is variability in the smoke features in the image. Therefore, it is valuable to study how to introduce the distance factor into current Transformer-based model to further improve the model performance in future work. Sixth, generative models such as the Stable Diffusion model (Rombach et al. 2022) can be used to generate synthetic scene datasets (Donida Labati et al. 2013). It is also worth further exploring the use of this model to supplement alarm data for various scenarios.
Declaration of funding
This research was funded by the Disciplines Distribution Project of Shenzhen, China (Grant Number: JCYJ20180508152055235).
Author contributions
W. F., Q. Y. M. and J. W. Y.: conceptualisation. Q. Y. M., W. F. and J. J. C.: methodology. Q. Y. M. and J. W. Y.: software. S. G. F.: formal analysis. L. X. and J. J. C.: data curation. Q. Y. M.: writing – original draft preparation. W. F., J. W. Y. and S. G. F.: writing – review and editing. Q. Y. M. and J. J. C.: visualisation. W. F. and S. G. F.: supervision. W. F.: funding acquisition. All authors have read and agreed to the published version of the manuscript.
References
Ahmed MR, Rahaman KR, Hassan QK (2018) Remote Sensing of Wildland Fire-Induced Risk Assessment at the Community Level. Sensors 18, 1570.
| Crossref | Google Scholar |
Amit Singh, Albert Haque, Alexandre Alahi, Serena Yeung, Michelle Guo, Jill R Glassman, William Beninati, Terry Platchek, Li Fei-Fei, and Arnold Milstein (2020) Automatic detection of hand hygiene using computer vision technology. Journal of the American Medical Informatics Association 27(8), 1316-1320.
| Crossref | Google Scholar |
Azim MR, Keskin M, Do N, Gül M (2022) Automated classification of fuel types using roadside images via deep learning. International Journal of Wildland Fire 31, 982-987.
| Crossref | Google Scholar |
Ba R, Chen C, Yuan J, Song W, Lo S (2019) SmokeNet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention. Remote Sensing 11, 1702.
| Crossref | Google Scholar |
Brock A, De S, Smith SL, Simonyan K (2021) High-performance large-scale image recognition without normalization. In ‘International Conference on Machine Learning’, 18–24 July 2021, ICML-22. pp. 1059–1071. Available at https://proceedings.mlr.press/v139/brock21a.html
Diakakis M, Xanthopoulos G, Gregos L (2016) Analysis of forest fire fatalities in Greece: 1977–2013. International Journal of Wildland Fire 25, 797-809.
| Crossref | Google Scholar |
Ding Z, Zhao Y, Li A, Zheng Z (2021) Spatial–Temporal Attention Two-Stream Convolution Neural Network for Smoke Region Detection. Fire 4, 66.
| Crossref | Google Scholar |
Ding Y, Deng W, Zheng Y, Liu P, Wang M, Cheng X, Bao J, Chen D, Zeng M (2022) IR-Net: Intra- and Inter-Human Relation Network for Multi-Person Pose Estimation. In ‘Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence’, IJCAI-22. pp. 855–862. (International Joint Conference on Artificial Intelligence)
Donida Labati R, Genovese A, Piuri V, Scotti F (2013) Wildfire smoke detection using computational intelligence techniques enhanced with synthetic smoke plume generation. IEEE Transactions on Systems, Man, and Cybernetics: Systems 43, 1003-1012.
| Crossref | Google Scholar |
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S (2021) An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In ‘International Conference on Learning Representations’, 3–7 May 2021, ICLR-21. Available at https://openreview.net/forum?id=YicbFdNTTy
Dufour D, Le Noc L, Tremblay B, Tremblay MN, Généreux F, Terroux M, Vachon C, Wheatley MJ, Johnston JM, Wotton M, Topart P (2021) A Bi-Spectral Microbolometer Sensor for Wildfire Measurement. Sensors 21, 3690.
| Crossref | Google Scholar |
Fernández-Berni J, Carmona-Galán R, Martínez-Carmona JF, Rodríguez-Vázquez Á (2012) Early forest fire detection by vision-enabled wireless sensor networks. International Journal of Wildland Fire 21, 938-949.
| Crossref | Google Scholar |
Glorot X, Bordes A, Bengio Y (2011) Deep Sparse Rectifier Neural Networks. In ‘Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics’, 11–13 April 2011, AISTATS. pp. 315–323. Available at https://proceedings.mlr.press/v15/
Göltaş M, Demirel T, Çağlayan İ (2017) Visibility Analysis of Fire Watchtowers Using GIS; A Case Study in Dalaman State Forest Enterprise. European Journal of Forest Engineering 3, 66-71.
| Google Scholar |
Guede-Fernández F, Martins L, de Almeida RV, Gamboa H, Vieira P (2021) A Deep Learning Based Object Identification System for Forest Fire Detection. Fire 4, 75.
| Crossref | Google Scholar |
Gutmacher D, Hoefer U, Wöllenstein J (2012) Gas sensor technologies for fire detection. Sensors and Actuators B: Chemical 175, 40-45.
| Crossref | Google Scholar |
He L, Gong X, Zhang S, Wang L, Li F (2021) Efficient attention based deep fusion CNN for smoke detection in fog environment. Neurocomputing 434, 224-238.
| Crossref | Google Scholar |
Jiang W, Wang F, Fang L, Zheng X, Qiao X, Li Z, Meng Q (2021) Modelling of wildland-urban interface fire spread with the heterogeneous cellular automata model. Environmental Modelling & Software 135, 104895.
| Crossref | Google Scholar |
Jiang W, Wang F, Su G, Li X, Wang G, Zheng X, Wang T, Meng Q (2022a) Modeling Wildfire Spread with an Irregular Graph Network. Fire 5, 185.
| Crossref | Google Scholar |
Jiang W, Wang F, Su G, Li X, Meng Q, Wang G (2022b) Key technologies of emergency management informatization for forest fires. China Safety Science Journal 32, 182-191.
| Google Scholar |
Hu J, Shen L, Sun G (2019) Squeeze-and-Excitation Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 23, 7132-7141.
| Google Scholar |
Johnston JM, Johnston LM, Wooster MJ, Brookes A, McFayden C, Cantin AS (2018) Satellite Detection Limitations of Sub-Canopy Smouldering Wildfires in the North American Boreal Forest. Fire 1, 28.
| Crossref | Google Scholar |
Kalatzis N, Avgeris M, Dechouniotis D, Papadakis-Vlachopapadopoulos K, Roussaki I, Papavassiliou S (2018) Edge computing in IoT ecosystems for UAV-enabled early fire detection. In ‘2018 IEEE international conference on smart computing’, 18–20 June 2018, SMARTCOMP-18. pp. 106–114. (IEEE Computer Society)
Khan S, Muhammad K, Hussain T, Ser JD, Cuzzolin F, Bhattacharyya S, Akhtar Z, de Albuquerque VHC (2021) DeepSmoke: Deep learning model for smoke detection and segmentation in outdoor environments. Expert Systems with Applications 182, 115125.
| Crossref | Google Scholar |
Khan F, Xu Z, Sun J, Khan FM, Ahmed A, Zhao Y (2022) Recent Advances in Sensors for Fire Detection. Sensors 22, 3310.
| Crossref | Google Scholar |
Ko B, Park J, Nam J-Y (2013) Spatiotemporal bag-of-features for early wildfire smoke detection. Image and Vision Computing 31, 786-795.
| Crossref | Google Scholar |
Larkin NK, Raffuse SM, Strand TM (2014) Wildland fire emissions, carbon, and climate: U.S. emissions inventories. Forest Ecology and Management 317, 61-69.
| Crossref | Google Scholar |
Loshchilov I, Hutter F (2017) Decoupled Weight Decay Regularization. In ‘7th International Conference on Learning Representations’, 6–9 May 2017, ICLR-17. Available at https://openreview.net/pdf?id=Bkg6RiCqY7
Luo S, Yan C, Wu K, Zheng J (2015) Smoke detection based on condensed image. Fire Safety Journal 75, 23-35.
| Crossref | Google Scholar |
Luo W, Li Y, Urtasun R, Zemel R (2016) Understanding the effective receptive field in deep convolutional neural networks. In ‘Advances in Neural Information Processing Systems’, 5–10 December 2016, NIPS-16. pp. 4898–4906. Available at https://proceedings.neurips.cc/paper_files/paper/2016/file/c8067ad1937f728f51288b3eb986afaa-Paper.pdf
Manzello SL, Almand K, Guillaume E, Vallerent S, Hameury S, Hakkarainen T (2018) FORUM position paper: The growing global wildland urban interface (WUI) fire Dilemma: Priority needs for research. Fire Safety Journal 100, 64-66.
| Crossref | Google Scholar |
Masoom SM, Zhang Q, Dai P, Jia Y, Zhang Y, Zhu J, Wang J (2022) Early Smoke Detection Based on Improved YOLO-PCA Network. Fire 5, 40.
| Crossref | Google Scholar |
Mell WE, Manzello SL, Maranghides A, Butry D, Rehm RG (2010) The wildlandurban interface fire problem current approaches and research needs. International Journal of Wildland Fire 19, 238-251.
| Crossref | Google Scholar |
Milecki A, Rybarczyk D (2020) The Gas Fire Temperature Measurement for Detection of an Object’s Presence on Top of the Burner. Sensors 20, 2139.
| Crossref | Google Scholar |
Ovadia Y, Fertig E, Ren J, Nado Z, Sculley D, Nowozin S, Snoek J (2019) Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift. In ‘Advances in Neural Information Processing Systems’, 8–14 December 2019. pp. 13969–13980. Available at https://doi.org/10.48550/arXiv.1906.02530
Podur J, Wotton M (2010) Will climate change overwhelm fire management capacity? Ecological Modelling 221, 1301-1309.
| Crossref | Google Scholar |
Qiang X, Zhou G, Chen A, Zhang X, Zhang W (2021) Forest fire smoke detection under complex backgrounds using TRPCA and TSVB. International Journal of Wildland Fire 30, 329-350.
| Crossref | Google Scholar |
Research F. A. (2017). Transforming and augmenting images: CenterCrop in Pytorch. Available at https://pytorch.org/vision/stable/transforms.html
Ryu J, Kwak D (2022) A Study on a Complex Flame and Smoke Detection Method Using Computer Vision Detection and Convolutional Neural Network. Fire 5, 108.
| Crossref | Google Scholar |
Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D (2020) Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. International Journal of Computer Vision 128, 336-359.
| Crossref | Google Scholar |
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. In ‘3rd International Conference on Learning Representations’, 7–9 May 2015, ICLR-15. Available at https://arxiv.org/abs/1409.1556
Sousa MJ, Moutinho A, Almeida M (2020) Thermal Infrared Sensing for Near Real-Time Data-Driven Fire Detection and Monitoring Systems. Sensors 20, 6803.
| Crossref | Google Scholar |
Tan M, Le Q (2019) EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks In ‘Proceedings of the 36th International Conference on Machine Learning’, 9–15 June 2019, ICML-2019. pp. 6105–6114. Available at https://proceedings.mlr.press/v97/tan19a.html
Tomkins L, Benzeroual T, Milner A, Zacher JE, Ballagh M, McAlpine RS, Doig T, Jennings S, Craig G, Allison RS (2014) Use of night vision goggles for aerial forest fire detection. International Journal of Wildland Fire 23, 678-685.
| Crossref | Google Scholar |
Stanford University (2020) CS231n Convolutional Neural Networks for Visual Recognition Visualizing what ConvNets learn. Available at http://cs231n.stanford.edu/2021
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł and Polosukhin I (2017) Attention is all you need. In ‘Advances in Neural Information Processing Systems’, 4–9 December 2017. pp. 5998–6008. Available at https://doi.org/10.48550/arXiv.1706.03762
Villacrés J, Arevalo-Ramirez T, Fuentes A, Reszka P, Auat Cheein F (2019) Foliar Moisture Content from the Spectral Signature for Wildfire Risk Assessments in Valparaíso-Chile. Sensors 19, 5475.
| Crossref | Google Scholar |
Wang S, Xiao X, Deng T, Chen A, Zhu M (2019) A Sauter mean diameter sensor for fire smoke detection. Sensors and Actuators B: Chemical 281, 920-932.
| Crossref | Google Scholar |
Xu G, Zhang Y, Zhang Q, Lin G, Wang Z, Jia Y, Wang J (2019) Video smoke detection based on deep saliency network. Fire Safety Journal 105, 277-285.
| Crossref | Google Scholar |
Ye Bai BW, Wu Y, Liu X (2022) 2021 Global Forest Fire Roundup. Fire Science and Technology S762, 705-709.
| Google Scholar |
Yuan F, Zhang L, Xia X, Huang Q, Li X (2020) A wave-shaped deep neural network for smoke density estimation. IEEE Transactions on Image Processing 29, 2301-2313.
| Crossref | Google Scholar |
Zhou Z, Shi Y, Gao Z, Li S (2016) Wildfire smoke detection based on local extremal region segmentation and surveillance. Fire Safety Journal 85, 50-58.
| Crossref | Google Scholar |
Zuo X (2022) Gather the powerful forces of fire fighting and rescue. China Emergency Management News 2, 1-3.
| Google Scholar |